Siphon: Streaming data ingestion with Apache Kafka
Data is at the heart of Microsoft’s cloud services, such as Bing, Office, Skype, and many more. As these services have grown and matured, the need to collect, process and consume data has grown with it as well. Data powers decisions, from operational monitoring and management of services, to business and technology decisions. Data is also the raw material for intelligent services powered by data mining and machine learning.
Most large-scale data processing at Microsoft has been done using a distributed, scalable, massively parallelized storage and computing system that is conceptually similar to Hadoop. This system supported data processing using a batch processing paradigm. Over time, the need for large scale data processing at near real-time latencies emerged, to power a new class of ‘fast’ streaming data processing pipelines.
Siphon – an introduction
Siphon was created as a highly available and reliable service to ingest massive amounts of data for processing in near real-time. Apache Kafka is a key technology used in Siphon, as its scalable pub/sub message queue. Siphon handles ingestion of over a trillion events per day across multiple business scenarios at Microsoft. Initially Siphon was engineered to run on Microsoft’s internal data center fabric. Over time, the service took advantage of Azure offerings such as Apache Kafka for HDInsight, to operate the service on Azure.
Here are a few of the scenarios that Siphon supports for Microsoft:
O365 Security: Protecting Office 365 customers’ data is a critical part of the business. A critical aspect of this is detecting security incidents in near real-time, so that threats can be responded to in a timely manner. For this, a streaming processing pipeline processes millions of events per second to identify threats. The key scenario requirements include:
- Ingestion pipeline that reliably supports multiple millions of events/second
- Reliable signal collection with integrated audit and alert
- Support O365 compliance certifications such as SOC and ISO
For this scenario, Siphon supports ingestion of more than 7 million events/sec at peak, with a volume over a gigabyte per second.
O365 SharePoint Online: To power analytics, product intelligence, as well as data-powered product features, the service requires a modern and scalable data pipeline for connecting user activity signals to the downstream services that consume these signals for various use cases for analytics, audit, and intelligent features. The key requirements include:
- Signals are needed in near real-time, with end to end latency of a few seconds
- Pipeline needs to scale to billions of events per day
- Support O365 compliance and data handling requirements
Siphon powers the data pub/sub for this pipeline and is ramping up in scale across multiple regions. Once the service was in production in one region, it was an easy task to replicate it in multiple regions across the globe.
MileIQ: MileIQ is an app that enables automated mileage tracking. On the MileIQ backend, there are multiple scenarios requiring scalable message pub/sub:
- Dispatching events between micro-services
- Data integration to the O365 Substrate
- ETL data for analytics
MileIQ is onboarding to Siphon to enable these scenarios which require near real-time pub/sub for 10s of thousands of messages/second, with guarantees on reliability, latency and data loss.
Siphon architecture
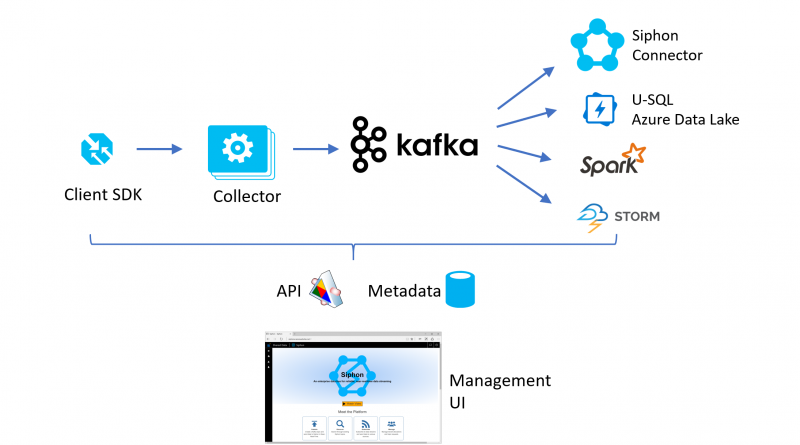
Siphon provides reliable, high-throughput, low-latency data ingestion capabilities, to power various streaming data processing pipelines. It functions as a reliable and compliant enterprise-scale ‘Data Bus.’ Data producers can publish data streams once, rather than to each downstream system; and data consumers can subscribe to data streams they need. Data can be consumed either via streaming platforms like Apache Spark Streaming, Apache Storm, and more, or through Siphon connectors that stream the data to a variety of destinations.
A simplified view of the Siphon architecture:

The core components of Siphon are the following:
- Siphon SDK: Data producers send data to Siphon using this SDK, that supports schematizing, serializing, batching, retrying and failover.
- Collector: This is a service with an HTTPS endpoint for receiving the data. In provides authentication, routing, throttling, monitoring and load balancing/failover.
- Apache Kafka: One more Kafka clusters are deployed as needed for the scenario requirements.
- Connectors: A service that supports config-driven movement of data from Siphon to various destinations, with support for filtering, data transformation, and adapting to the destination’s protocol.
These components are deployed in various Microsoft data centers / Azure regions to support business scenarios. The entire system is managed as a multi-user/multi-tenant service with a management layer including monitoring and alerting for system health, as well as an auditing system for data completeness and latency.
Siphon’s journey to HDInsight
When the Siphon team considered what building blocks they needed to run the service on Azure, the Apache Kafka for HDInsight service was an attractive component to build on. The key benefits are:
- Managed service: The HDInsight service takes care of Apache Kafka cluster creation, and keeping the clusters up and running, and routine maintenance and patching, with an overall SLA of 99.9 percent.
- Compliance: HDInsight meets a number of security and compliance requirements and is a good foundation from which Siphon could build additional capabilities needed to meet the stringent needs of services like Office 365.
- Cost: Innovations such as integration of the Kafka nodes with Azure Managed Disks enable increased scale and reduced cost without sacrificing reliability.
- Flexibility: HDInsight gives the flexibility to customize the cluster both in terms of the VM type and disks used, as well as installation of custom software, and tuning the overall service for the appropriate cost and performance requirements.
Siphon was an early internal customer for the Apache Kafka for HDInsight (preview) service. Implementation of the Azure Managed Disk integration enabled lowering the overall cost for running this large scale ‘Data Bus’ service.
Siphon currently has more than 30 HDInsight Kafka clusters (with around 600 Kafka brokers) deployed in Azure regions worldwide and continues to expand its footprint. Cluster sizes range from 3 to 50 brokers, with a typical cluster having 10 brokers, with 10 disks attached to each broker. In aggregate, these Siphon clusters support ingesting over 4 GB of data per second at peak volumes.
Apache Kafka for HDInsight made it easy for Siphon to expand to new geo regions to support O365 services, with automated deployments bringing down the time to add Siphon presence in a new Azure region to hours instead of days.
Conclusion
Data is the backbone of Microsoft's massive scale cloud services such as Bing, Office 365, and Skype. Siphon is a service that provides a highly available and reliable distributed Data Bus for ingesting, distributing and consuming near real-time data streams for processing and analytics for these services. Siphon relies on Apache Kafka for HDInsight as a core building block that is highly reliable, scalable, and cost effective. Siphon ingests more than one trillion messages per day, and plans to leverage HDInsight to continue to grow in rate and volume.
Get started with Apache Kafka on Azure HDInsight.
Source: Azure Blog Feed