Performance best practices for using Azure Database for PostgreSQL – Connection Pooling
This blog is a continuation of a series of blog posts to share best practices for improving performance and scale when using Azure Database for PostgreSQL service. In this post, we will focus on the benefits of using connection pooling and share our recommendations to improve connection resiliency, performance, and scalability of applications running on Azure Database for PostgreSQL. If you have not read the previous performance best practice blogs in the series, we would highly recommend reading the following blog posts to learn, understand, and adopt the recommended best practices for using Azure Database for PostgreSQL service.
- Performance best practices for using Azure Database for PostgreSQL
- Performance updates and tuning best practices for using Azure Database for PostgreSQL
- Performance troubleshooting best practices using Azure Database for PostgreSQL features
In PostgreSQL, establishing a connection is an expensive operation. This is attributed to the fact that each new connection to the PostgreSQL requires forking of the OS process and a new memory allocation for the connection. As a result, transactional applications frequently opening and closing the connections at the end of transactions can experience higher connection latency, resulting in lower database throughput (transactions per second) and overall higher application latency. It is therefore recommended to leverage connection pooling when designing applications using Azure Database for PostgreSQL. This significantly reduces connection latency by reusing existing connections and enables higher database throughput (transactions per second) on the server. With connection pooling, a fixed set of connections are established at the startup time and maintained. This also helps reduce the memory fragmentation on the server that is caused by the dynamic new connections established on the database server.
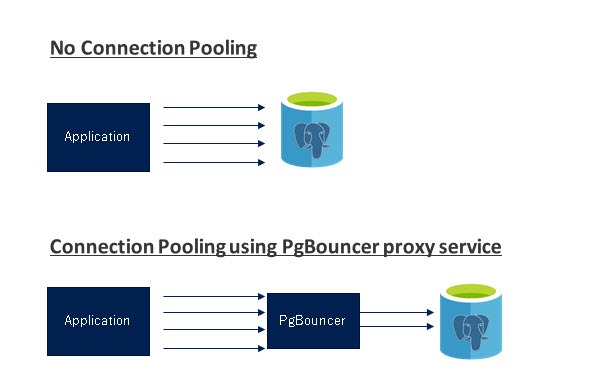
The connection pooling can be configured on the application side if the app framework or database driver supports it. If that is not supported, the other recommended option is to leverage a proxy connection pooler service like PgBouncer or Pgpool running outside the application and connecting to the database server. Both PgBouncer and Pgpool are developed by the community and can be used with Azure Database for PostgreSQL. As we continue on, we will focus our conversation on PgBouncer in the context of real user experiences.
PgBouncer is a lightweight connection pooler that can be installed on the virtual machine (VM) running the application. The application connects to the PgBouncer proxy service running locally on the VM while PgBouncer service in-turn connects to the Azure Database for PostgreSQL service using the credentials and configuration settings specified in the pgbouncer.ini file. The maximum number of connections and default pool size can be defined in the configuration settings in pgbouncer.ini. 
If your application is containerized and running on Azure Kubernetes Service (AKS), you can run PgBouncer as a sidecar proxy. As part of our commitment to provide native integration of best in class OSS databases with Azure’s industry leading ecosystem, we have published a PgBouncer sidecar proxy image in Microsoft container registry. PgBouncer sidecar runs with the application container in the same pod in AKS and provides connection pooling proxy to Azure Database for PostgreSQL. If the application container fails over or restarts, the sidecar container will follow thereby providing high availability with connection resiliency and predictable performance. Visit the docker hub page to learn more on how to access and use this image. For best practices around development with Azure Kubernetes Services, we would recommend to follow the documentation, “Connecting Azure Kubernetes Service and Azure Database for PostgreSQL.”
To give some estimates of the performance improvement when using PgBouncer for connection pooling with Azure Database for PostgreSQL, we ran a simple performance benchmark test with pgbench. pgbench provides a configuration setting to create new connection for every transaction so we leveraged that to measure the impact of connection latency on throughput of the application. The following are the observations with A/B testing comparing throughput with standard pgbench benchmark testing with and without PgBouncer. In the test, we ran pgbench with scale factor of 5 against Azure Database for PostgreSQL running on general purpose tier with 2 vCores (GP_Gen5_2). The only variable during the tests was PgBouncer. With PgBouncer, the throughput improved 4x times as shown below while connection latency was reduced by 40 percent.

PgBouncer, with its built-in retry logic can further ensure connection resiliency, high availability, and transparent application failover during the planned (scheduled/scale-up/scale-down) or unplanned failover of the database server. The retry logic is found to be very useful for OSS applications like CKAN or Apache Airflow using SQLAlchemy. Without the use of PgBouncer, the database failover events require the application service to be restarted for connections to be re-established following a connection failure. In this scenario, it is also important to set connection timeout sufficiently higher than the retry interval to allow retry attempts to proceed before timing out.
To summarize, as new connections are an expensive operation with PostgreSQL, especially for applications which opens new connections frequently, we highly recommend using connection pooling while running applications against Azure Database for PostgreSQL. If the application is not designed to leverage connection pooling out of the box you can leverage PgBouncer as a connection pooling proxy. The benefits of running application with PgBouncer proxy are:
- Improved throughput and performance
- No connection leaks by defining the maximum number of connections to the database server
- Improved connection resiliency against restarts
- Reduced memory fragmentation
We hope that you are taking advantage of Azure Database for PostgreSQL. Please continue to provide feedback on the features and functionality that you want to see next. If you need any help or have questions, please check out the “Azure Database for PostgreSQL Documentation.” You can also reach out to us by emailing the Ask Azure DB for PostgreSQL alias, and be sure to follow us on Twitter @AzureDBPostgres and #postgresql for the latest news and announcements.
Acknowledgements
Special thanks to Diana Putnam, Rachel Agyemang, Sudhakar Sannakkayala, Sunil Agrawal, Sunil Kamath, Bhavin Gandhi, Anitah Cantele, and Prabhat Tripathi for their contributions to this posting.
Source: Azure Blog Feed