New automated machine learning capabilities in Azure Machine Learning service
As part of Azure Machine Learning service general availability, we are excited to announce the new automated machine learning (automated ML) capabilities. Automated ML allows you to automate model selection and hyperparameter tuning, reducing the time it takes to build machine learning models from weeks or months to days, freeing up more time for them to focus on business problems. The making of automated ML was driven by our commitment to improve the productivity of data scientists and democratize AI. By simplifying machine learning, automated ML enables domain experts in the businesses to rapidly build and deploy machine learning solutions.
In this blog post, we will:
- Highlight the new automated ML capabilities of that are available today as part of Azure Machine Learning service
- Walk you through the motivation, underlying technology, and principles behind automated ML
New capabilities
Since the preview of Azure Machine Learning service just a couple of months ago, we have added many compelling capabilities.
Training infrastructure
Machine learning training jobs are very compute intensive, and training time is highly dependent on the size of the dataset and the type of algorithm. As a result, training is often a bottleneck and the ability to complete jobs quickly enables data scientists to iterate fast. With automated ML, you have many choices for compute infrastructure that you can run your training jobs with. Start by running your jobs on your local machine and scale up and out using the Azure cloud.
Azure Machine Learning compute
When you are ready to scale, automated ML enables you to run your training jobs in the Azure Cloud by scaling up as well as running multiple training jobs in parallel using Azure Machine Learning compute or Azure Databricks clusters. With Azure Machine Learning compute, you can setup a cluster of Azure Virtual Machines to run your training jobs in parallel. Autoscaling ensures that virtual machines are shut down when the training jobs are complete, saving you costs.
Azure Databricks (preview)
Azure Databricks is a managed Spark offering on Azure that is popular with big data processing. With automated machine learning on Azure Databricks, customers who use Azure Databricks can now use the same cluster to run automated machine learning experiments, allowing data to remain in the same place. You can leverage the local worker nodes with autoscale and auto termination capabilities.
Local computer
Often data scientists start training machine learning models on their local computer with down sampled data. Constraints such as the data governance and security policies of organizations may require data to stay on-premises. With automated ML, you can run your training jobs entirely on your local machine without data ever leaving your computer, complying with data security and protection needs.
Data pre-processing and featurization
Data Scientists spend a large percentage of their time on data cleaning, transformation, and generating new features. Automated ML simplifies many of these data pre-processing tasks by automatically transforming categorical features into one hot encoding, imputing missing values and rows, generating new date time features, and more.
Visual charts
Automated ML comes with rich visual charts such as a leaderboard of all the candidate models built by automated ML. Also included are many different metrics of each model and charts to help visualize/compare model performance such as confusion matrices. Visual charts are integrated into Jupyter notebooks via an extension so that you never have to leave the comfortable notebook experience. The charts are also available on Azure Portal for those who use a different IDE.
Forecasting (preview)
In addition to classification and regression, we now support forecasting. Time series forecasting is a common problem and has applications in many industries. For example, retail companies want to forecast future product sales and energy utilities want to forecast power consumption demand. It is critical to ensure model tuning takes into consideration windows of time and aggregation to tune a model for optimal performance. When using the forecasting capability, automated machine learning optimizes our pre-processing, algorithm selection and hyperparameter tuning to recognize the nuances of time series datasets. Our service expands our support for feature engineering with greater focus on things like grain index featurization and grouping and missing row imputation to provide greater model performance and accuracy.
Model Explain Ability (preview)
Most businesses run on trust and being able to open the ML “black box” helps build transparency and trust. In heavily regulated industries like healthcare and banking, it is critical to comply with regulations and best practices. One key aspect of this is understanding the relationship between input variables (features) and model output. Knowing both the magnitude and direction of the impact each feature (feature importance) has on the predicted value helps better understand and explain the model. With model explain ability, we enable you to understand feature importance as part of automated ML runs.
Region availability
Azure Machine Learning service is available in many regions in U.S (east and west coast), Europe, Asia and Australia. Having automated ML available in a region near you will help reduce the network latency. If your data is subject to data sovereignty and governance rules, you can choose to use automated ML that is available in your geography to adhere to these requirements.
Why automated machine learning?
Machine learning is complex
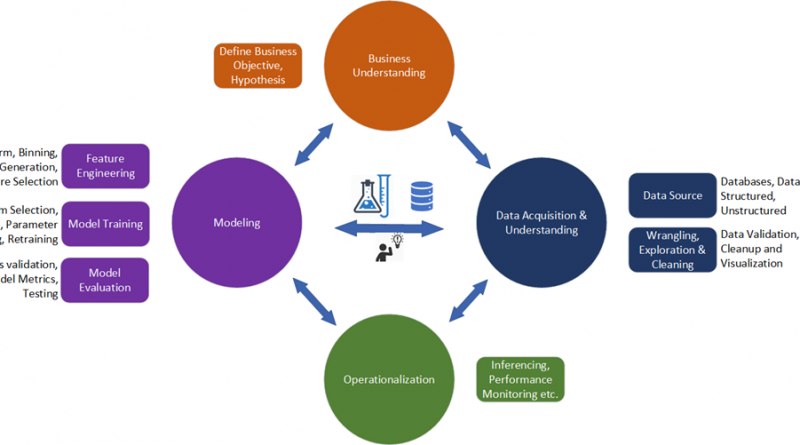
Developing machine learning solutions is complex, tedious and time consuming. The typical machine learning lifecycle consists of four parts: business understanding, data acquisition, modeling, and operationalization. Every Machine Learning solution should start with the business problem you are working to solve followed by acquiring and exploring the data that is needed.

In the feature engineering part of the modeling stage, you need to transform the input data via techniques such as removing nulls, rescaling, selecting for features, and/or generating new features. Next, you choose which machine learning algorithm is most suitable – a support vector machine (SVM), logistic regression, or a tree-based classifier? What parameter values should be used for the chosen algorithm (ex. the max depth and min split count for a tree-based classifier)? And many more. Just look at this “simple” tutorial chart from the scikit-learn machine learning library to see the complexity of algorithm selection:

Source: scikit-learn machine learning library
In short, data scientists and developers face a series of sequential and interconnected decisions along the way to achieving "magical" machine learning solutions. Ultimately, all these decisions will determine the accuracy of the machine learning pipeline – it comes down to the combination of data pre-processing / feature engineering steps, learning algorithms, and hyperparameter settings that go into each machine learning solution.
Due to this variability, data scientists typically build several models with different combinations of features, learners and hyper parameters. These models are then evaluated to optimal accuracy and the most suitable is selected. Building multiple models and evaluating them is tedious and often takes many weeks. When machine learning solutions need to be updated as data evolves, data scientists would need to repeat the same feature engineering, model training and evaluation process.
Simplifying machine learning
But what if a developer or data scientist could access an automated service that identifies the best machine learning pipelines for their labelled data? The Automated ML capability in the Azure Machine Learning service provides this solution. Automated ML empowers users, with or without data science expertise, to identify an end-to-end machine learning pipeline for any problem, achieving a high quality machine learning model while spending far less of their time. It enables a significantly larger number of experiments to be run, resulting in faster iteration towards production-ready solutions.

Microsoft is committed to democratizing AI through our products. By simplifying and removing the need to tune models, hyperparameters manually, we are boosting the productivity of the users. By making automated ML available through the Azure Machine Learning service, we're empowering data scientists and organizations to build, deploy and manage the machine learning life cycle from end to end.
If you are new to data science, automated ML will help you get started quickly. Simplify the machine learning model building process by abstracting away the complexity of feature engineering, algorithm selection and hyperparameter tuning. This will enable more people in your organization to leverage machine learning and most importantly allow domain experts to rapidly prototype ML solutions and validate their hypothesis before involving data scientists.
If you are an experienced data scientist, automated ML will let you improve productivity and save time by eliminating the need to manually perform the tedious and repetitive tasks of feature engineering, algorithm selection and hyperparameter tuning. You can even start by generating a model with automated ML as a starting point and tune it further. Organizations can also use automated ML to benchmark their models.
Many Fortune 500 customers are benefiting from using automated ML. These include a global oil & refinery enterprise that’s using automated ML to forecast reservoir production and a medical devices company that’s using automated ML for predictive maintenance. Automated ML also powers Microsoft Power BI’s AI capabilities, where business analysts can build machine learning models without writing a single line of code.
What’s behind automated machine learning?
Azure Machine Learning service’s automated ML capability is based on a breakthrough from our Microsoft Research division and different from competing solutions in the market. The approach combines ideas from collaborative filtering and Bayesian optimization to search an enormous space of possible machine learning pipelines intelligently and efficiently. It's essentially a recommender system for machine learning pipelines. Similar to how streaming services recommend movies for users, automated ML recommends machine learning pipelines for data sets.
")
Streaming service (numbers represent user ratings for movies)
")
Automated ML (numbers represent accuracy of pipelines evaluated on datasets)
As indicated by the distributions shown on the right side of the figures above, automated ML also takes uncertainty into account, incorporating a probabilistic model to determine the best pipeline to try next. This approach allows automated ML to explore the most promising possibilities without exhaustive search, and to converge on the best pipelines for the user’s data faster than competing “brute force” approaches.
We trained automated ML’s probabilistic model by running hundreds of millions of experiments, each involving evaluation of a pipeline on a data set. This training allows automated ML to find good solutions quickly for your new problems. Automated ML continues to learn and improve today as it runs on new ML problems – even though it does not see your data. More about that next.
Design principles
At Microsoft our mission is to democratize machine learning by simplifying model building and improving the productivity of data scientists. We also place a strong emphasis on trust and data privacy. The principles behind automated ML seek to further the mission.
Data privacy
Automated ML is designed to generate pipelines without having to see the customer’s data, preserving privacy. Customer data and execution of the machine learning pipeline both live in the customer’s cloud subscription (or their local machine), which they have complete control of. Only the results of each pipeline run are sent back to the automated ML service, which then makes an intelligent, probabilistic choice of which pipelines should be tried next.
No need to “see” the data

Get started easily— Python SDK
Python is one of the most popular languages for building machine learning solutions due to the availability of numerous libraries such as numpy, matplotlib and machine learning frameworks such as scikit-learn, PyTorch, and TensorFlow. Users leverage all of these tools by downloading and installing libraries. Azure Machine Learning service uses the same paradigm— download and install the Azure Machine Learning service Python SDK which includes the automated ML capability. As a result, an intuitive and simple to use API is all it takes to run automated ML training jobs.
Bring to the IDEs that you are already familiar with
There are several Python development environments available for data scientists use. Those from a development background may prefer an IDE like PyCharm or VS Code. Data scientists who work with other team members may be using Jupyter Notebooks. Our goal is to bring automated ML to the development environments you use and are familiar with. Part of the Azure Machine Learning service Python SDK, automated ML works in any Python environment. All you need to do is download and install the SDK like any other Python libraries that you use. Automated ML has extensions for Jupyter Notebooks, which will help you visualize automated ML runs, monitor jobs, inspect stats without leaving the notebook environment.
Open source frameworks – sci-kit-learn, LightGBM
Machine Learning is innovating at very rapid pace thanks to an active open source community and rich set of open source frameworks. Many solutions today were simply unimaginable a few years ago. At Microsoft, our goal is to support popular frameworks and not get your organization locked into a proprietary framework. This helps organizations to innovate quickly without being stifled by proprietary frameworks.
Control and transparency
When building machine learning solutions, data scientists must inspect many attributes of machine learning models to and carefully weigh the trade-offs of each before choosing an optimal for a given business problem. Speed and automation versus accuracy, simple and interpretable versus complex and accurate, the list goes on. We want to provide complete control and transparency into all the models that automated ML generates so you can choose the best one for your scenario by making the tradeoffs that make sense for your business problem. The models and pipelines automated ML generates are regular Python pipelines that you are free to deconstruct and further tune.
Explore
We created automated ML to make machine learning more accessible for data scientists of all levels of experience. Get started by visiting our documentation and let us know what you think – we are committed to make automated ML better for you!
Source: Azure Blog Feed