Provision on-demand Spark clusters on Docker using Azure Batch's infrastructure
Since its release 3 years ago, Apache Spark has soared in popularity amongst Big Data users, but is also increasingly common in the HPC space. However, spinning up a Spark cluster, on-demand, can often be complicated and slow. Instead, Spark developers often share pre-existing clusters managed by their company's IT team. In these scenarios, Spark developers run their Spark applications on static clusters that are in constant flux between under-utilization and insufficient capacity. You're either out of capacity, or you're burning dollars on idle nodes.
I'm excited to announce our beta release of the Azure Distributed Data Engineering Toolkit – an open source python CLI tool that allows you to provision on-demand Spark clusters and submit Spark jobs directly from your CLI.
After closely studying how Spark users interact with their clusters, we designed the Azure Distributed Data Engineering Toolkit to extend the native Spark experience, allowing you to provision clusters, and giving you the full end-to-end experience of running Spark at scale. Furthermore, this toolkit inherits Azure Batch's fast provision time, taking only 3-5 minutes to provision your Spark cluster. With a Spark native experience and fast spin-up time, this toolkit allows you to easily run your Spark experiments, enabling you to do more, easily and in less time.
For those of you who need specific software pre-installed for your Spark application, this toolkit also gives you the ability to bring your own Docker image, making setup simple and reproducible.
The Azure Distributed Data Engineering Toolkit is free to use – you only pay for the cores you consume. Because it is built on Azure Batch, it has the ability to provision low-priority VMs, letting you run your Spark jobs at an 80% discount, making it a great tool for experimentation, testing, and other low priority work.
Today, this toolkit only supports Spark, however, we plan to support other distributed data engineering frameworks in a similar vein.
Create your Spark cluster
Once you have the Azure Distributed Data Engineering Toolkit installed you can start by creating a Spark cluster with this simple CLI command:
$ aztk spark cluster create
--id <my_spark_cluster_id>
--size <number_of_nodes>
--vm-size <vm_size>
Instead of using –size, you can optionally use –size-low-priority to provision low priority VMs.
You can also add the –username and –ssh-key parameters to create an user for the cluster. This can optionally be done in a separate aztk spark cluster add-user command.
Submit a job
Once your Spark cluster is ready, submit jobs against your cluster(s) with the standard spark-submit command using the aztk spark cluster submit command.
$ aztk spark cluster submit
--id <my_spark_cluster>
--name <my_spark_job_name>
[options]
<app jar | python file>
[app parameters]
And just like with the standard spark-submit command, the output will be streamed to the console.
Quick start demo
Here's an example of how you can get a 2TB Spark cluster with low-priority VMs (80% discounted) in about 5 minutes:
$ aztk spark cluster create --id my_cluster --size-low-pri 16 --vm-size Standard_E16_v3 # Grab some coffee... # BOOM! Your 2TB Spark cluster is up. Start submitting jobs! $ aztk spark cluster submit --id my_cluster --name my_massive_job my_pyspark_app.py
Interactive mode
To get started, most users will want to work interactively with their Spark clusters. The Azure Distributed Data Engineering Toolkit supports working interactively with the aztk spark cluster ssh command that helps you ssh into the cluster's master node, but also helps you port-forward your Spark Web UI and Spark Jobs UI to your local machine:
$ aztk spark cluster ssh --id <my_spark_cluster_id>
By default, we port forward the Spark Web UI to localhost:8080, Spark Jobs UI to localhost:4040, and Jupyter to localhost:8888. These defaults can be configured in the .thunderbolt/ssh.yaml file, if needed.
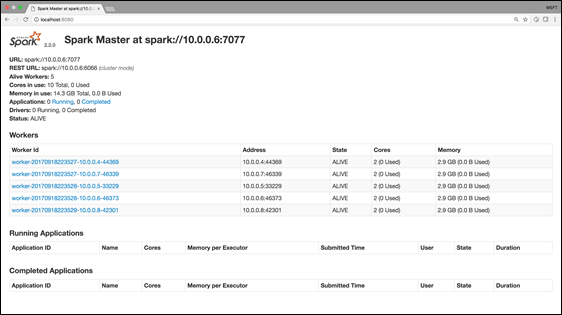
Once you run the command, you should be able to interact with your Spark Web UI by going to localhost:8080 on your local machine:

Managing your Spark cluster(s)
Checkout some of the other commands you can use to manage your Spark cluster(s):
# Get a summary of all the Spark clusters you have created with Azure Thunderbolt $ aztk spark cluster list # Get a summary on a specific Spark cluster $ aztk spark cluster get --id <my_spark_cluster_id> # Delete a specific Spark cluster $ aztk spark cluster delete --id <my_spark_cluster_id>
We look forward to you using these capabilities and hearing your feedback. Please contact us at askaztk@microsoft.com for feedback or feel free to contribute to our Github repository.
Additional information
- Download and get started with the Azure Distributed Data Engineering Toolkit
- Please feel free to submit issues via Github
Additional resources
- See Azure Batch, the underlying Azure service used by the Azure Distributed Data Engineering Toolkit
- More general purpose HPC on Azure
Source: Big Data