Bring your own vocabulary to Microsoft Video Indexer
Self-service customization for speech recognition
Video Indexer (VI) now supports industry and business specific customization for automatic speech recognition (ASR) through integration with the Microsoft Custom Speech Service!
ASR is an important audio analysis feature in Video Indexer. Speech recognition is artificial intelligence at its best, mimicking the human cognitive ability to extract words from audio. In this blog post, we will learn how to customize ASR in VI, to better fit specialized needs.
Before we get in to technical details, let’s take inspiration from a situation we have all experienced. Try to recall your first days on a job. You can probably remember feeling flooded with new words, product names, cryptic acronyms, and ways to use them. After some time, however, you can understand all these new words. You adapted yourself to the vocabulary.
ASR systems are great, but when it comes to recognizing a specialized vocabulary, ASR systems are just like humans. They need to adapt. Video Indexer now supports a customization layer for speech recognition, which allows you to teach the ASR engine new words, acronyms, and how they are used in your business context.
How does Automatic Speech Recognition work? Why is customization needed?
Roughly speaking, ASR works with two basic models – an acoustic model and a language model. The acoustic model is responsible for translating the audio signal to phonemes, parts of words. Based on these phonemes, guesses regarding how these phonemes can be sequenced into words know to the system’s lexicon are generated. The language model is then used to choose the most reasonable sequence of words out of these guesses, based on the probabilities of words to occur one after the other, as learned from large samples of text.
When input speech contains new words, the system cannot propose them as guesses, and they won’t be recognized correctly. For instance, Kubernetes, a new Azure product, is a word that we will teach VI to recognize in the example below. In other cases, the words exist, but the language model is not expecting them to appear in a certain context. For example, container service is not a 2-word sequence that a non-specialized language model would be scoring highly probable.
How does customization work?
Video Indexer lets you customize speech recognition by uploading adaptation text, namely text from the domain whose vocabulary you’d like the engine to adapt to. New words appearing in the adaptation text will now be recognized, assuming default pronunciation, and the language model will learn new probable sequences of words.
An example
Let’s take a video on Azure Containers as an example. First, we upload the video to video indexer, without adaptation. Go to the VI portal, click 'upload’, and choose the file from your machine.
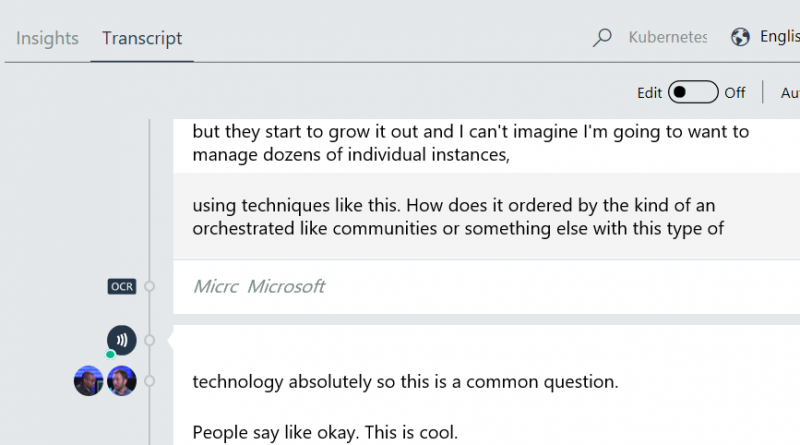
After a few minutes, the video on Kubernetes will be indexed (view result). Let us see where adaptation can help. Go 9 minute and 46 seconds into the video. The word ‘Kubernetes’ is a new, highly specific, word that the system does not know, and is therefore recognized as “communities”.

Here are two other examples. At 00:49, “a VM” was recognized as “IBM”. Again, specific domain vocabulary, this time an acronym. The same happens for “PM” at 00:17, where it is not recognized.

To solve these, and other, issues, we need to apply language adaptation. We will start with a partial solution, which will help us understand the full solution.
Example 1: Partial adaptation – words without context
VI allows you to provide adaptation text that introduces your vocabulary to the speech recognition system. At this point, we will introduce just three lines, each with a word including Kubernetes, VM, and PM. The file is available for your review.
Go to the customization settings by clicking on the highlighted icon on the upper-right hand corner of the VI portal, as shown below:

On the next screen, click “add file”, and upload the adaptation file.

Make sure you activate the file as adaptation data.

After the model has been adapted, re-index the file. And… Kubernetes is now recognized!

VM is also recognized, as well as PM at 00:17.

However, there is still room for more adaptation. Manually adding words can only help so much, since we cannot cover all the words, and we would also like the language model to learn from real instances of the vocabulary. This will make use of context, parts of speech, and other cues which can be learned from a larger corpus. In the next example, we will take a more complete approach by adding a decent corpus of real sentences from the domain.
Example 2: Adapting the language model
Similar to what we have done above, let us now use as adaptation text a few pages of documentation about Azure containers. We have collected this adaptation text for your review. Below is an example for this style of adaptation data:
To mount an Azure file share as a volume in Azure Container Instances, you need three values: the storage account name, the share name, and the storage access key… The task of automating and managing a large number of containers and how they interact is known as orchestration. Popular container orchestrators include Kubernetes, DC/OS, and Docker Swarm, all of which are available in the Azure Container Service.
We recommend taking a look at the whole file. Let’s see a few examples of the effect. Let’s go back to 09:46. “Orchestrated” became orchestrator because of the adaptation text context.

Here is another nice example in which highly specific terms become recognizable.
Before adaptation:

After adaptation:

Do’s and don’ts for language model adaptation
The system learns based on probabilities of word combinations, so to learn best:
- Give enough real examples of sentences as they would be spoken, hundreds to thousands is a good base.
- Put only one sentence per line, not more. Otherwise the system will learn probabilities across sentences.
- It is okay to put one word as a sentence to boost the word against others, but the system learns best from full sentences.
- When introducing new words or acronyms, if possible, give as many examples of usage in a full sentence to give as much context as possible to the system.
- Try to put several adaptation options, and see how they work for you.
Some patterns to avoid in adaptation data:
- Repetition of the exact same sentence multiple times. It does not boost further the probability and may create bias against the rest of the input.
- Including uncommon symbols (~, # @ % &) as they will get discarded, as well as the sentence they appear into.
- Putting too large inputs, including hundreds of thousands of sentences. These will dilute the effect of boosting.
Using the VI language adaptation API
To support adaptation, we have added a new customization tab to the site, and a new web API to manage the adaptation texts, training of the adaptation text, and transcription using adapted models.
In the Api/Partner/LinguisticTrainingData web API you will be able to create, read, update, and delete the adaptation text files. The files are plain *.txt files which contain your adaptation data. For an improved user experience, mainly in the UI, we have groups that each file belongs to. This is especially useful when wanting to disable or enable multiple files at once in the UI.
After adaptation data files are uploaded, we need to use them to customize the system using the Api/Partner/LinguisticModel API's, which creates a linguistic model based on one or more files. In cases where there is more than a single file provided we concatenate the files into a single one. Preparing a customized model can take several minutes, and you are required to make sure that your model status is "Complete" before using it in indexing.
The last and most important step is the transcription itself. We added to the upload a new field named “linguisticModel” that accept a valid, customized linguistic model ID to be used for transcription. When re-indexing, we use the same model ID provided in the original indexing.
Important note: There is a slight difference in the user experience when using our site and API. When using our site, we allow enabling/disabling training data files and groups, and we will choose the active model during file upload/re-index. When using the API, we disregard the active state and index the videos based on model ID provided at run time. This difference is intentional to allow both simplicity in our website and more a robust experience for developers.
The full API can be found in our developer portal.
Conclusion
Adaptation for speech recognition is necessary in order to teach the ASR system new words and how they are being used in a domain’s vocabulary. In Video Indexer, we provide adaptation technology which takes nothing but adaptation text and modifies the language model in the ASR system to make more intelligent guesses, given that the transcribed speech comes from the same domain as the adaptation text. This is useful to teach your system acronyms (e.g. VM), new words (e.g. Kubernetes), and new uses of known words (e.g. container).
Source: Azure Blog Feed