A closer look at Azure Data Lake Storage Gen2
On June 27th, 2018 we announced the preview of Azure Data Lake Storage Gen2 the only data lake designed specifically for enterprises to run large scale analytics workloads in the cloud. Azure Data Lake Storage Gen2 takes core capabilities from Azure Data Lake Storage Gen1 such as a Hadoop compatible file system, Azure Active Directory and POSIX based ACLs and integrates them into Azure Blob Storage. This combination enables best in class analytics performance along with Blob Storage’s tiering and data lifecycle management capabilities and the fundamental availability, security and durability capabilities of Azure Storage.
In this blog post, we are going to drill into why Azure Data Lake Storage Gen2 is unique. Taking a closer look at the innovative Hadoop file system implementation, Azure Blob Storage integration and a quick review of why Azure Data Lake Storage Gen2 enables the lowest total cost of ownership in the cloud.
High-Fidelity server side Hadoop file system with hierarchical namespace
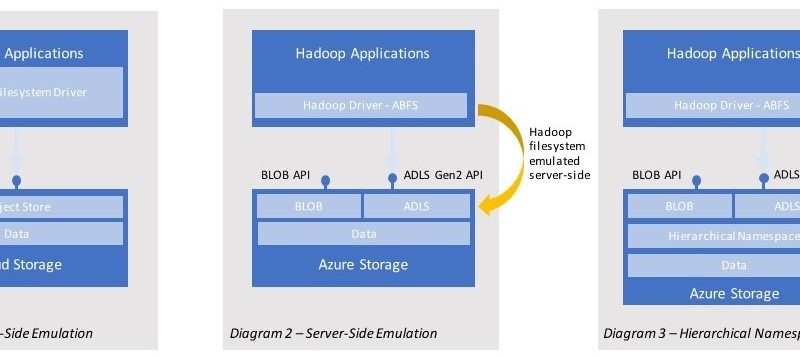
The simplest way to enable Hadoop applications to work with cloud storage is to build a Hadoop File System driver which runs client-side within the Hadoop applications as illustrated in diagram 1. This driver emulates a file system, converting Hadoop file system operations into operations on the backend of the respective platforms. This is often inefficient, and correctness is hard to implement/achieve. For instance, when implemented on an object store a request by a Hadoop client to rename a folder (a common operation in Hadoop jobs) can result in many REST requests. This is because object stores use a flat namespace and don’t have the notion of a folder. For example, renaming a folder with 5,000 items in it can result in 10,000 REST calls from the client . This means 5,000 to copy the child objects to a new destination and 5,000 to delete the original files. This approach performs poorly, often affecting the overall time a job takes to complete. It is also error prone because the operation is not atomic and a failure at any point will result in the job failing with data in an inconsistent state.

In diagram 2 we illustrate how Azure Data Lake Storage Gen2 moves this file-system logic server side along-side our Blob APIs, enabling the same data to be accessed via our BLOB REST APIs or the new Azure Data Lake Storage Gen2 file system APIs. This enables file system operation like a rename to be performed in a single operation. Server-side we are still mapping these requests to our underlying Blob Storage and its flat namespace making this approach more optimal than the first model and offering higher fidelity with Hadoop for some operations, however it doesn’t enable atomicity of these operations.
In addition to moving the file system support server side, we have also designed a cloud scale hierarchical namespace that integrates directly in the Azure Blob Storage. Diagram 3 shows how once enabled the hierarchical namespace provides first class support for files and folders including support for atomic operations such as copy and delete on files and folders. Namespace functionality is available to both Azure Data Lake Storage Gen2 and Blob APIs allowing for consistent usage across both set of APIs. By general availability the same data will be accessible using both BLOB and Azure Data Lake Storage Gen2 APIs with full coherence.
Azure Data Lake Storage Gen2 is building on Blob Storage’s Azure Active Directory integration (in preview) and RBAC based access controls. We are extending these capabilities with the aid of the hierarchical namespace to enable fine-grained POSIX-based ACL support on files and folders. Azure Active Directory integration and POSIX-based ACLs will be delivered during the preview.
Azure Blob Storage integration
Because Azure Data Lake Storage Gen2 is integrated into the Azure Storage platform, applications can use either the BLOB APIs or Azure Data Lake Storage Gen2 file system APIs for accessing data. BLOB APIs allow you to leverage your existing investments in BLOB Storage and continue to take advantage of the large ecosystem of first and third party applications already available while the Azure Data Lake Storage Gen2 file system APIs are optimized for analytics engines like Hadoop and Spark.
Additional benefits from integration with Azure Storage include:
- Unlimited scale and performance due to significant advances made in storage account architecture.
- Performance improvements when reading and writing individual objects resulting in significantly higher throughput and concurrency.
- Removes the need for customers to have to decide a priority whether they want to run analytics or not at the data ingestion time. In Azure Storage we believe all data can and will be used for analytics.
- Data protection capabilities including all data being encrypted at rest using either Microsoft or customer manager keys.
- Integrated network Firewall capabilities that allow you to define rules restricting access to only requests originating from specified networks.
- Durability options such as Zone Redundant Storage and Geo-Redundant Storage to enable your applications to be designed for high-availability and disaster recovery.
- Linux integration – BlobFUSE allows customers to mount Blob Storage from their Linux VMs and interact with Azure Data Lake Storage Gen2 using standard Linux shell commands.
Of course, Azure Storage is built on a platform grounded in strong consistency guaranteeing that writes are made durable before acknowledging success to the client. This is critically important for big data workloads where the output from one task is often the input to the next job. This greatly simplifies development of big data applications since they do not have to work around issues that surface with weaker consistency models such as eventual consistency.
Minimize total cost of ownership
Azure Data Lake Storage Gen2 delivers cloud scale HDFS compatible support optimized for big data workloads such as Hadoop and Spark. With an integrated hierarchical namespace, you now have all the advantages of a file system with the scale and cost typically only associated with object stores. In addition to Blob storage capacity pricing, Azure Data Lake Storage Gen2 also allows you to reduce the cost of your analytics jobs by enabling analytics engines to run more efficiently using a combination of improved storage performance and the ability to perform complex file system operations in a single operation. Azure Data Lake Storage Gen2 also helps you to minimize the total cost of ownership of data over the lifetime of that data using a combination of Blob storage capacity prices, integrated tiering, and lifecycle management policies that enable your data to be tiered from hot to cool to the lowest priced archival solution in the cloud.
Getting started evaluating Azure Data Lake Storage Gen2
To find out more you can:
- Begin your evaluation of Azure Data Lake Storage and sign up for the preview.
- Watch this video to learn how you can get started with Azure Data Lake Storage Gen2.
- Learn more about key capabilities and features of Azure Data Lake Storage Gen2.
- ADLS Gen2 is now available on HDInsight as well. Read more about this integration along with the updates to Hadoop, Spark, and other open source frameworks.
Source: Big Data