Spoken Language Identification in Video Indexer
We are excited to share that Video Indexer has a new capability, Spoken Language Identification (LID)!
A common ask from our customers has been to enable indexing of videos or batches of videos, without manually providing their language. This is especially important for batch uploads. To support this, we have introduced automatic spoken language identification to Video Indexer. The identified language is used to invoke the appropriate speech-to-text model.
LID is based on state of the art Deep Learning applied on the audio. LID currently supports eight languages including English, Chinese, French, German, Italian, Japanese, Spanish, and Russian. It works with high accuracy for high-to-mid quality recordings. We are working on adding more languages to the list, so stay tuned.
Let’s learn more about LID in Video Indexer.
Using LID in Video Indexer
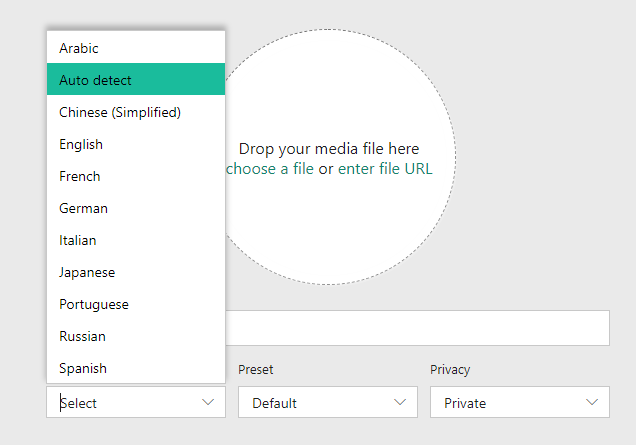
To use the LID capability, you have two options. If you use the portal, you can now select Auto detect in the language selection combo box when uploading a video.

If you use the API to upload a video, use auto as the language parameter value.
Attribute sourceLanguage in the video index JSON under root/videos/insights is assigned the detected language, and attribute sourceLanguageConfidence:

Note to the user
- The model behind LID works best with clear recordings: broadcast materials and enterprise materials such as podcasts, lectures, tutorials, etc.
- The model may be confused by: noisy recordings, low-quality recordings, highly variant acoustics, and heavy accents.
- When the model cannot yield a result with high confidence, VI will fall back to English.
Behind the curtains
Many cognitive tasks, including spoken language identification, are easy for humans but still very challenging for computers. One way to approach this type of tasks, is to mimic the human brain. The initial idea of an artificial neural network was proposed more than 70 years ago. The state of the art in the field is called Deep Learning and is being successfully used for different tasks in Speech and Language Understanding, Computer Vision and even outperforming humans in some tasks, such as diagnosis of skin cancer.
In VI, we harness the power of Deep Learning for Spoken Language Identification. We train the network by presenting it with a huge number of speech examples, coming from different speakers and having diverse acoustic conditions.
The figure below shows how we represent speech to the network. This representation turns voice into an image called a spectrogram. A spectrogram gives us a sense of how complex acoustics are, as 30 seconds of speech can easily require 300,000 pixels!

Legend: Phonetic visualization of a speech smaple. Top: Waveform representation of the recorded audio. Bottom: Spectrogram representation.
The network learns from such huge amounts of data by looking for patterns in the spectrograms, which differentiate between languages. A good pattern is a pattern that is typical to one language. Deep learning starts with a random guess on what these patterns are. Then, using the examples from each language, improves the guess in the right direction. Here is a fun example of what a rolling "R" in Spanish looks like on a spectrogram.
Conclusion
LID is useful when one needs to index videos whose dominant language is not known. LID is based on advanced Deep Learning modeling and works best for high- to mid-quality recordings. We are expanding LID to cover more acoustic environments. Please try LID on the Video Indexer web portal and visit our Video Indexer developer portal, for details on the API. We are looking forward to hearing on your experience with LID!
Have querstions or feedback? We would love to hear from you! Use our UserVoice to help us prioritize features, or email VISupport@Microsoft.com.
Source: Azure Blog Feed