Globally replicated data lakes with LiveData using WANdisco on Azure
The recent announcement of Azure Data Lake Storage Gen2 preview and its support on Azure HDInsight is already leading partners to innovate at a global scale. WANdisco enables globally replicated data lakes on Azure for analytics over the freshest data. This blog explains how.
The modern business landscape is ruled by data. Analytics and AI are now essential for driving key business transformation. Customers have benefited tremendously from the performance, flexibility, and low cost offered by Azure for analytics and AI workloads.
Hybrid made easy with a single-click!
For many organizations, however, the process of making their data available in the cloud has been a challenge. The sheer scale of modern data sets combined with the expectations from users of continued system availability make it difficult to use standard tooling for copying data just to get data to Azure. They cannot suffer the business cost of system downtime, nor the potential for inconsistent or unavailable data that produces incorrect analytics results.
The organizations that are maximizing their Azure opportunities are using WANdisco Fusion to ensure they have always accurate and consistent data. Let’s look at an example of how a customer was able to leverage WANdisco on Azure HDInsight and reduce their deployment time from months to days.
Scenario: replicating data from on-prem to cloud and other Hadoop distributions
Customer wanted to synchronize data from on-prem Hadoop to Azure HDInsight for analytics and then replicate to a third data lake in parent company in real-time, always, with no downtime, with strict SLAs.
Challenge: Petabytes across on-prem and the cloud
Multiple petabyte under replication across on-prem and the cloud. Data along with the metadata such as Hive schema, authorization policies using Ranger etc. was constantly changing and used at the source and the destination. Customer wanted a zero-disruption solution.
Solution: deploy WANdisco Fusion with a single-click in Azure HDInsight
With hundreds of terabytes of data needing to be in sync with Azure all the time, Customer was able to deploy WANdisco Fusion with a single-click in Azure HDInsight Application Platform and was able to support the complex data availability, multi-vendor and multi-location support, while ensuring their data SLAs.
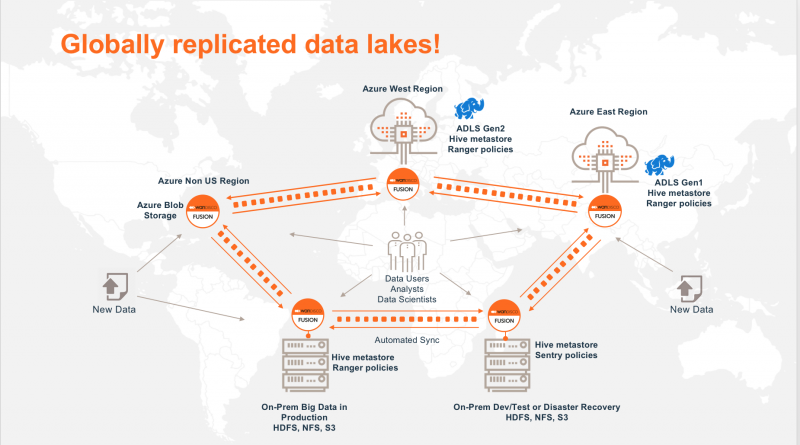
Globally replicated data lakes!
With WANdisco Fusion, you can make data that you have used in other large-scale analytics platforms available in Azure Blob Storage, ADLS Gen1 and Gen2 without downtime or disruption to your existing environment. Customers can also replicate the data, and metadata (Hive database schema, authorization policies using Apache Ranger, Sentry, and more ) across different regions to make the data lake available globally for analytics.

The technology to make this happen is WANdisco Fusion, and the capability is called ‘LiveData.’ LiveData combines distributed consensus with large-scale data replication, so that applications can continue to operate on data locally, while WANdisco Fusion makes that same information available in Azure Blob Storage, Azure Data Lake Storage Gen2 and Gen1. Systems can operate on data in either platform at the same time, while WANdisco Fusion's LiveData technology ensures that data are available for use at any time in any location.
LiveData in practice
As an example of how a LiveData platform is used, a semiconductor manufacturer applies this technology today to bridge their on-premises analytics infrastructure with Azure. Large-scale Hadoop deployments run on-premises with hundreds of Terabytes of data in constant use. Making that data available in Azure Data Lake Storage (ADLS) would be impossible without a LiveData platform because it is undergoing constant change. There is no time for downtime, so data need to be replicated while they are changing and being used.
WANdisco Fusion achieves this by introducing consensus to changes made in the environments. Deployed in both the on-premises Hadoop environments, and in Azure, Fusion lets administrators select which portions of their data need to be available in each environment. That selective replication in combination with continuous replication of data, as soon as any change occurs, can be used to bring data at scale to the cloud. The LiveData capability does even more! The semiconductor manufacturer also has to ensure that their applications will operate in Azure on Azure Data Lake Storage Gen2 on exactly the same data that they use on-premises. With a LiveData platform, this manufacturer is able to guarantee consistency by actively replicating changes multi-directionally, a new critical business and technology capability.
By introducing WANdisco Fusion on-premises and in Azure, linking those deployments and defining simple rules for data availability (directory, database, table, and more) and spanning locations, an enterprise is able to avoid the physical constraints that would otherwise prevent ready adoption of Azure Data Lake Storage Gen2 and other Azure analytical services. Applications can continue to run on-premises while data are replicated with Azure, and applications can be operated in the Azure environment on the very same data at the same time. A LiveData architecture avoids the divergence of data by removing the notion of having separate data in each environment. Instead, both the on-premises and Azure deployments have direct access at local speed to the same data all the time.
Try WANdisco to create globally replicated data lakes today!
Getting there is simple, with three steps:
- Installing WANdisco Fusion App on HDInsight using a single-click deployment model
- Install WANdisco Fusion on-premises
- Connect to the data sources in each region and choose the datasets to replicate.
Replication rules can act on file system locations or on specific Hive databases and tables, Ranger and sentry policies etc. Applications can then use their data as normal. With local speed of access and no need to modify how the applications work, Fusion provides continuous replication and guaranteed consistency for those data sets that are shared across environments.
Resources
- Install WANdisco Fusion App on Azure HDInsight
- Install WANdisco Fusion Server
- Learn more about Azure HDInsight
- User Guide for WANdisco
Source: Azure Blog Feed