GPUs vs CPUs for Deployment of Deep Learning Models
This blog post was co-authored by Mathew Salvaris, Senior Data Scientist, Azure CAT and Daniel Grecoe, Senior Software Engineer, Azure CAT
Choosing the right type of hardware for deep learning tasks is a widely discussed topic. An obvious conclusion is that the decision should be dependent on the task at hand and based on factors such as throughput requirements and cost. It is widely accepted that for deep learning training, GPUs should be used due to their significant speed when compared to CPUs. However, due to their higher cost, for tasks like inference which are not as resource heavy as training, it is usually believed that CPUs are sufficient and are more attractive due to their cost savings. However, when inference speed is a bottleneck, using GPUs provide considerable gains both from financial and time perspectives. In a previous tutorial and blog Deploying Deep Learning Models on Kubernetes with GPUs, we provide step-by-step instructions to go from loading a pre-trained Convolutional Neural Network model to creating a containerized web application that is hosted on Kubernetes cluster with GPUs using Azure Container Service (AKS).
Expanding on this previous work, as a follow up analysis, here we provide a detailed comparison of the deployments of various deep learning models to highlight the striking differences in the throughput performance of GPU versus CPU deployments to provide evidence that, at least in the scenarios tested, GPUs provide better throughput and stability at a lower cost.
In our tests, we use two frameworks Tensorflow (1.8) and Keras (2.1.6) with Tensorflow (1.6) backend for 5 different models with network sizes which are in the order of small to large as follows:
- MobileNetV2 (3.4M parameters)
- NasNetMobile (4.2M parameters)
- ResNet50 (23.5M parameters)
- ResNet152 (58.1M parameters)
- NasNetLarge (84.7M parameters)
We selected these models since we wanted to test a wide range of networks from small parameter efficient models such as MobileNet to large networks such as NasNetLarge.
For each of these models, a docker image with an API for scoring images have been prepared and deployed on four different AKS cluster configurations:
- 1 node GPU cluster with 1 pod
- 2 node GPU cluster with 2 pods
- 3 node GPU cluster with 3 pods
- 5 node CPU cluster with 35 pods
The GPU clusters were created using Azure NC6 series virtual machines with K80 GPUs while the CPU cluster was created using D4 v2 virtual machines with 8 cores. The CPU cluster was strategically configured to approximately match the largest GPU cluster cost so that a fair throughput per dollar comparison can be made between the 3 node GPU cluster and 5 node CPU cluster which is close but slightly more expensive at the time of these tests. For more recent pricing, please use Azure Virtual Machine pricing calculator.
All clusters were set up in East US region and testing of the clients occurred using a test harness in East US and Western Europe. The purpose was to determine if testing from different regions had any effect on throughput results. As it turns out, testing from different regions had some, but very little influence and therefore the results listed in this analysis only include data from the testing client in the East US region with a total of 40 different cluster configurations.
The tests were conducted by running an application on an Azure Windows virtual machine in the same region as the deployed scoring service. Using a range of 20-50 concurrent threads, 1000 images were scored, and the results recorded was the average throughput over the entire set. Actual sustained throughput is expected to be higher in an operationalized service due to the cyclical nature of the tests. The results reported below use the averages from the 50 thread set in the test cycle, and the application used to test these configurations can be found on GitHub.
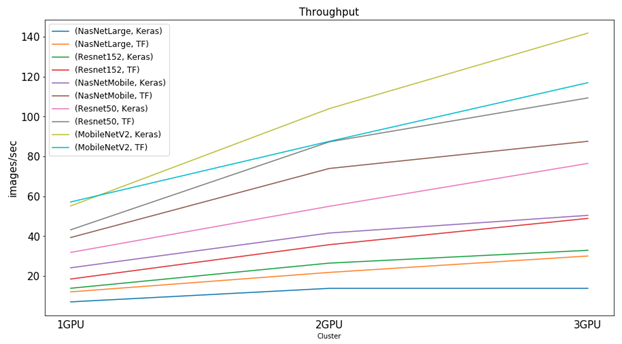
Scaling of GPU Clusters
The general throughput trends for GPU clusters differ from CPU clusters such that adding more GPU nodes to the cluster increases throughput performance linearly. The following graph illustrates the linear growth in throughput as more GPUs are added to the clusters for each framework and model tested.

Due to management overheads in the cluster, although there is a significant increase in the throughput, the increase is not proportional to the number of GPUs added and is less than 100 percent per GPU added.
GPU vs CPU results
As stated before, the purpose of the tests is to understand if the deep learning deployments perform significantly better on GPUs which would translate to reduced financial costs of hosting the model. In the below figure, the GPU clusters are compared to a 5 node CPU cluster with 35 pods for all models for each framework. Note that, the 3 node GPU cluster roughly translates to an equal dollar cost per month with the 5 node CPU cluster at the time of these tests.

The results suggest that the throughput from GPU clusters is always better than CPU throughput for all models and frameworks proving that GPU is the economical choice for inference of deep learning models. In all cases, the 35 pod CPU cluster was outperformed by the single GPU cluster by at least 186 percent and by the 3 node GPU cluster by 415 percent which is of similar cost. These results are more pronounced for smaller networks such as MobileNetV2 for which the single node GPU cluster performs 392 percent and 3 node GPU 804 percent better than the CPU cluster for TensorFlow framework.
It is important to note that, for standard machine learning models where number of parameters are not as high as deep learning models, CPUs should still be considered as more effective and cost efficient. Also, there exists methods to optimize CPU performance such as MKL DNN and NNPACK. However, similar methods also exist for GPUs such as TensorRT. We also found that the performance on GPU clusters were far more consistent than CPU.
We hypothesize that this is because there is no contention for resources between the model and the web service that is present in the CPU only deployment. It can be concluded that for deep learning inference tasks which use models with high number of parameters, GPU based deployments benefit from the lack of resource contention and provide significantly higher throughput values compared to a CPU cluster of similar cost.
We hope that you find this comparison beneficial for your next deployment decision and let us know if you have any questions or comments.
Source: Azure Blog Feed