Release models at pace using Microsoft’s AutoML!
What is the real problem?
When creating a machine learning model, data scientists across all industry segments face the following challenges: Defining and tuning the hyperparameters, and deciding which algorithm to use.
If a customer plans to create a ML model that will predict the price of a car, the data scientist will need to pick up the right algorithm and hyperparameters. Narrowing down to the best algorithm and hyperparameters is a time-consuming process. This has been a challenge for Microsoft’s customers across all verticals, and Microsoft recently launched an Azure Machine Learning python SDK that has AutoML module. The AutoML module helps with not only defining and tuning hyperparameters but also picking the right algorithm!
What is AutoML?
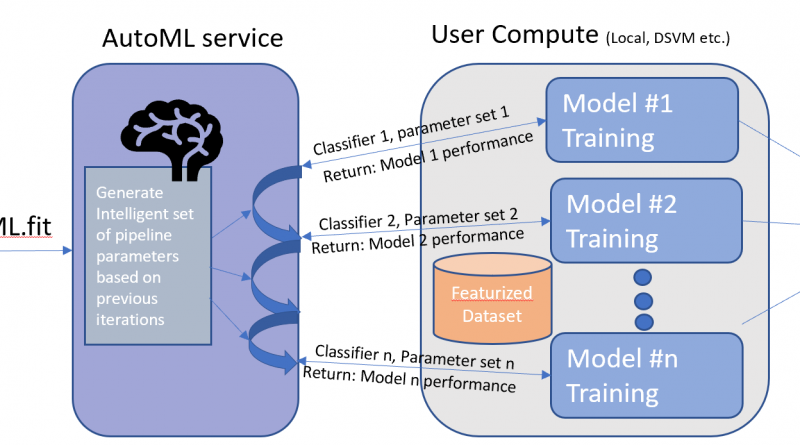
AutoML helps create high quality model using intelligent automation and optimization. AutoML will figure out the right algorithm and hyper parameters to use. It is a tool that will improve the efficiency of data scientist!

AutoML’ s current capabilities
AutoML currently supports the problem spaces regression and classification. Additional problem spaces such as clustering will be supported in future releases. From a data pre-processing perspective, AutoML allows one hot encoding (converting categorical variable to binary vector) and assign values to missing fields. It currently supports Python language and scikit-learn framework. For training the model, one could use laptop/desktop, Azure Batch AI or Databricks or Azure DSVM. All scikit-learn supported data formats are currently supported.
High level steps to execute AutoML methods
a) Create and activate a conda environment
conda create -n myenv Python=3.6 cython numpy

conda activate myenv
b) Pip install the Azure ML Training SDK

c) Launch the Jupyter notebook

d) Setup the machine learning resources through API
 Additional components are created in the resource group as part of executing the commands in the below cell
Additional components are created in the resource group as part of executing the commands in the below cell


You can write the workspace information to a local config which aids in loading the config to other Jupyter notebook files if required

Sample_Project is created…


e) Invoke AutoML fit method
AutoMLClassifier(params) -> Specify # of Iterations, Metric to optimize, etc.
Example
automl_classifier = AutoMLClassifier(experiment = experiment,
name = experiment_name,
debug_log = 'automl_errors.log',
primary_metric = 'AUC_weighted',
max_time_sec = 12000,
iterations = 10,
n_cross_validations = 2,
verbosity = logging.INFO)
AutoMLClassifier.fit(X, Y,….) -> Intelligently generates pipeline parameters to train data
Example
local_run = automl_classifier.fit(X=X_digits, y=y_digits, show_output=True)
f) Check the run details and pick the optimal one

g) The final step is to operationalize the most performant model
Availability
The SDK will be publicly available for use after the Ignite conference, which ends on September 28, 2018. It will be available in westcentralus, eastus2 and west Europe to name a few Azure regions.
Conclusion
AutoML is a leap towards the future of Data Science. It is bound to not only make data scientists working for any organization efficient because AutoML will automatically run multiple iterations of your experiment but also enable new or experienced data scientists to explore different algorithms and select and tune hyperparameters because AutoML will help do this. It is worth noting that the data scientists can start on a local machine leveraging the Azure ML Python SDK which has AutoML. Data scientist can then use the power of cloud to run the training/iterations using technologies such as Azure Batch AI or Databricks or Azure DSVM.
Further reading
Some of the modules with the Azure ML Python SDK are already in public preview and you can find more details by reading our documentation. If you are new to data science, Azure ML studio is a great starting point.
Source: Azure Blog Feed