Cross-channel emotion analysis in Microsoft Video Indexer
Many different customers across industries want to have insights into the emotional moments that appear in different parts of their media content. For broadcasters, this can help create more impactful promotion clips and drive viewers to their content; in the sales industry it can be super useful for analyzing sales calls and improve convergence; in advertising it can help identify the best moment to pop up an ad, and the list goes on and on. To that end, we are excited to share Video Indexer’s (VI) new machine learning model that mimics humans’ behavior to detect four cross-cultural emotional states in videos: anger, fear, joy, and sadness.
Endowing machines with cognitive abilities to recognize and interpret human emotions is a challenging task due to their complexity. As humans, we use multiple mediums to analyze emotions. These include facial expressions, voice tonality, and speech content. Eventually, the determination of a specific emotion is a result of a combination of these three modalities to varying degrees.
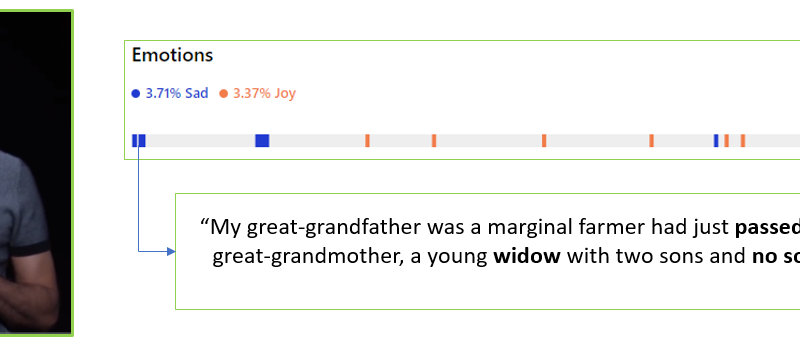
While traditional sentiment analysis models detect the polarity of content – for example, positive or negative – our new model aims to provide a finer granularity analysis. For example, given a moment with negative sentiment, the new model determines whether the underlying emotion is fear, sadness, or anger. The following figure illustrates VI’s emotion analysis of Microsoft CEO Satya Nadella’s speech on the importance of education. At the very beginning of his speech, a sad moment was detected.

All the detected emotions and their specific appearances along the video are enumerated in the video index JSON as follows:

Cross-channel emotion detection in VI
The new functionality utilizes deep learning to detect emotional moments in media assets based on speech content and voice tonality. VI detects emotions by capturing semantic properties of the speech content. However, semantic properties of single words are not enough, so the underlying syntax is also analyzed because the same words in a different order can induce different emotions.

VI leverages the context of the speech content to infer the dominant emotion. For example, the sentence “… the car was coming at me and accelerating at a very fast speed …” has no negative words, but VI can still detect fear as the underlying emotion.
VI analyzes the vocal tonality of speakers as well. It automatically detects segments with voice activity and fuses the affective information contained within with the speech content component.

With the new emotion detection capability in VI that relies on speech content and voice tonality, you are able to become more insightful about the content of your videos by leveraging them for marketing, customer care, and sales purposes.
For more information, visit VI’s portal or the VI developer portal, and try this new capability for free. You can also browse videos indexed as to emotional content: sample 1, sample 2, and sample 3.
Have questions or feedback? We would love to hear from you!
Use our UserVoice to help us prioritize features, or email VISupport@Microsoft.com with any questions.
Source: Azure Updates