Design patterns – IoT and aggregation
In this article, you will learn how to insert IoT data with high throughput and then use aggregations in different fields for reporting. To understand this design pattern, you should already be familiar with Azure Cosmos DB and have a good understanding of change feed, request unit (RU), and Azure Functions. If these are new concepts for you, please follow the links above to learn about them.
Many databases achieve extremely high throughput and low latency because they partition the data. This is true for all NoSQL database engines like MongoDB, HBase, Cassandra, or Azure Cosmos DB. All these databases can scale out unlimitedly because of partitioning or sharding.
Let us look at Azure Cosmos DB more closely. On the top level, a container is defined. You can think of container as a table, a collection, or a graph but this is the main entity which holds all the information. Azure Cosmos DB uses the word “container” to define this top-level entity, and because Azure Cosmos DB is a multi-model database this container is synonymous with collections for SQL, MongoDB, and Graph APIs, and Tables for Cassandra or Table APIs.
A collection has many physical partitions which are allocated based on the throughput requirement of the collection. Today, for 10000 RU you may get ten partitions, but this number may change tomorrow. You should always focus on the throughput you want and should not worry about the number of partitions you got allocated, as I said, this number of partitions will change with data usage.
To achieve high scale throughput and low latency, you need to specify a partition key and row key while inserting the data and use the same partition key and row key while reading the data. If you choose the right partition key then your data will be distributed evenly across all the partitions, and the read and write operations can be in single digit milliseconds.
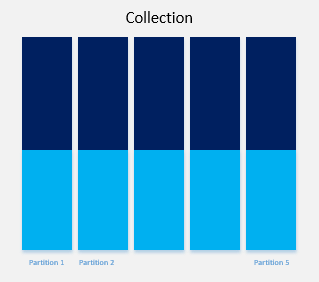
Internally, Azure Cosmos DB uses hash-based partitioning. When you write an item, Azure Cosmos DB hashes the partition key value and uses the hashed result to determine which partition to store the item in. A good partition key will distribute your data equally among all the available partitions as shown in the figure below.

Good partition key, data is equally distributed
One to one mapping between partition keys and physical partitions doesn’t exist, meaning a single physical partition can store many keys. This is because on is a logical concept (partition key) and the other is a physical concept. Often novice users think that a partition key is equal to a physical partition. Please remember, one is a logical concept and the other is a physical concept, they are not mapped one to one. Each key is hashed and then using modulo operators, it is mapped to a partition. Each logical partition can store 10 GB of data, this limit may change in future and will automatically split when the data grows to more than 10 GB. Though you never have to worry about splitting partitions yourself, Azure Cosmos DB does it behind the scene. However, you should never have a partition key that may have more than 10 GB of data.
Now, let’s look at an example. You are working in an IoT company, which has IoT devices installed in buildings to maintain the temperature, and you have hundreds of thousands of customers all around the world. Each customer has thousands of IoT devices which are updating the temperature every minute. Let’s define how the data will look:
{
CustomerId: Microsoft,
DeviceId: XYZ-23443,
Temperature: 68
DateTime: 32423512
}
Imagine you have a customer which is a global company with offices in every country and has 100,000 IoT devices distributed. These devices are sending 2 KB of data every minute for a daily total of 2 GB. At this rate, you may fill the partition in five days. you can use a time to live (TTL) mechanism to delete the data automatically, but for our example let’s assume you have to keep this data for 30 days.
If you choose “CustomerId” as the partition key, you will see your data is skewed for large customers and your partitions will look as shown below.

This kind of partitioning will also create throttling for large customers, who have thousands of IoT devices and are inserting the data in a collection partitioned on “CustomerId”. You may wonder why it will be throttled? To understand that, imagine your collection is defined to have 5000 RU/Sec and you have five partitions. This means each partition throughput can have 1000 RU.
Please note, we said here five partitions but this number is again here for discussion's sake. This number may change in the future for your throughput. With the change in hardware, tomorrow you may just get three partitions or one for 5000 RU. Remember, these physical partitions are not constant, they will keep splitting automatically as your data will keep growing.
Users often make this mistake and then complain that they are being throttled at 2000 RU even if they have provisioned the collection for 5000 RU. In this scenario, the main issue is their data is not partitioned properly and they are trying to insert 2000 RU into one partition. This is why you need to have a good partition key that can distribute your data evenly across all partitions.
If “CustomerId” is not a good partition key, then what other keys we can use? You will also not like to partition the data on “DateTime”, because this will create a hot partition. Imagine you have partitioned the data on time, then for a given minute, all the calls will hit one partition. If you need to retrieve the data for a customer then it will be a fan-out query because data may be distributed on all the partitions.
To choose the right partition keys, you must think and optimize for read or write scenarios. For simpler scenarios, it is possible to get a partition key for both read and write scenarios. However, if that is not the case then you must compromise and optimize for one of the scenarios.
In this article, we are exploring the scenario in which we do not have one right partition key for both read and write. Let’s see what we can do to satisfy both the read and write requirements.
In this scenario, we have to optimize for writing because of a high number of devices sending us the data. It is best to define the collection with “DeviceId” as the partition key for fast ingestion. “DeviceId” is not only unique but also more granular than “CustomerId”. Always look for a key with more cardinality or uniqueness so your data will be distributed across all partitions. However, what if for reporting you want to do aggregation over “CustomerId”?
This is the crux of this blog. You would like to partition the data for the insert scenario and also group the data on a different partition key for the reporting scenario. Unfortunately, these are mismatched requirements.
Imagine, you have inserted the data with “DeviceId” as the partition key, but if now you want to group by temperature and “CustomerId”, your query will be a cross-partition query. Cross-partition queries are ok for once a while scenario. Since all data is indexed by default in Azure Cosmos DB, cross-partition queries are not necessarily bad things, but they can be expensive. Cross-partition queries cost you much more RU/s than point lookups.
You have two options to solve this problem. Your first option is to use Azure Cosmos DB’s change feed and Azure Function to aggregate the data per hours and then store the aggregated data in another collection, where “CustomerId” is the partition key.
 Change Feed
Change Feed
You can again listen to the change feed of reports per hour collection to aggregate the data for per day and store the aggregation in another Azure Cosmos DB reports per day. IoT devices send data directly to Cosmos DB. This pattern is possible because of change feed. Change feed exposes the log of Cosmos DB. The change feed includes inserts and updates operations made to documents within the collection. Read more about change feed. However, please know that change feed is enabled by default for all account and for all collections.
To learn more about how to use change feed and azure function, check this screen cast.
The second option is to use Spark, to do the aggregation, and keep the aggregated value in SQL data warehouse or a second collection where the partition key is CustomerId.
 This option will also use the change feed. From Spark, you can connect directly to change feed and get all the changes in Spark at the real-time. Once the data is in Spark, you can do the aggregation and then write that data back to Azure Cosmos DB or to SQL Data Warehouse.
This option will also use the change feed. From Spark, you can connect directly to change feed and get all the changes in Spark at the real-time. Once the data is in Spark, you can do the aggregation and then write that data back to Azure Cosmos DB or to SQL Data Warehouse.
Here is the code snippet for Spark to read the data from Azure Cosmos DB, do the aggregation and write back the data.
# Base Configuration
iotConfig = {
"Endpoint" : "https://xx.documents.azure.com:443/",
"Masterkey" : "E0wCMaBIz==",
"Database" : "IoT",
"preferredRegions" : "Central US;East US2",
"Collection" : "IoT",
"checkpointLocation" : "dbfs://checkpointPath"
}
# Connect via Spark connector to create Spark DataFrame
iot_df = spark.read.format("com.microsoft.azure.cosmosdb.spark").options(**iotConfig).load()
iot_df.createOrReplaceTempView("c")
psql = spark.sql ("select DeviceId, CustomerId, Temp from c")
writeConfig = {
"Endpoint" : "https://xx.documents.azure.com:443/",
"Masterkey" : "E0wCMaBKdlALwwMhg==",
"Database" : "IoT",
"preferredRegions" : "Central US;East US2",
"Collection" : "MV",
"Upsert" : "true"
}
iot_df.createOrReplaceTempView("c")
psql = spark.sql ("select CustomerId, avg(temp) as Temp_Avg from c group by c.CustomerId ")
psql.write.format("com.microsoft.azure.cosmosdb.spark").mode('append').options(**writeConfig).save()
Check the screen cast to learn how to use Spark with Azure Cosmos DB.
Both the options can give you per minute aggregation by listening to the live change feed. Depending upon your reporting requirement, you can keep different aggregations at different levels in different collections or in the same collection. This is another option you can have to keep these aggregated values to SQL data warehouse.
Source: Azure Blog Feed