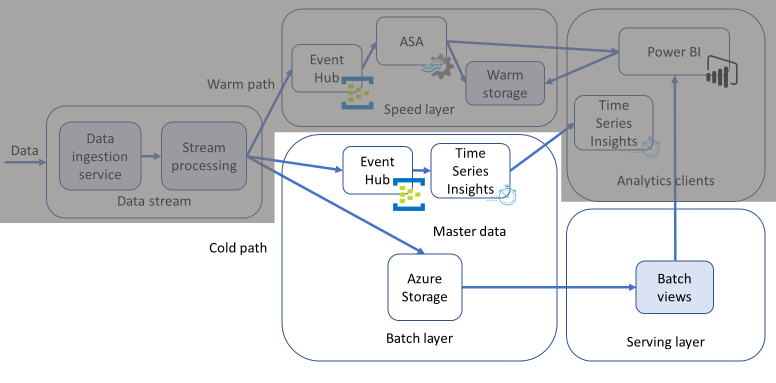
Extracting insights from IoT data using the cold path data flow
This blog continues our coverage of the solution guide published by Microsoft’s Industry Experiences team. The guide covers the following components:
- Ingesting data
- Hot path processing
- Cold path processing
- Analytics clients
We already covered the recommendation for processing data for an IoT application in the solution guide and suggested using Lambda architecture for data flow. To reiterate the data paths:
- A batch layer (cold path) stores all incoming data in its raw form and performs batch processing on the data. The result of this processing is stored as a batch view. It is a slow-processing pipeline, executing complex analysis, combining data from multiple sources over a longer period (such as hours or days), and generating new information such as reports and machine learning models.
- A speed layer and a serving layer (warm path) analyzes data in real time. This layer is designed for low latency, at the expense of accuracy. It is a faster-processing pipeline that archives and displays incoming messages, and analyzes these records, generating short-term critical information and actions such as alarms.
This blog post covers the cold path processing components of the solution guide.

We have covered timeseries analysis with Azure Time Series Insights (TSI) in detail in the solution guide. It is an analytics, storage, and visualization service for timeseries data. Please read the relevant section for the use of TSI.
As you may remember from previous blog posts, we are using the sample data published by the NIST SMS Test Bed endpoint. Our previous posts ended with the data pushed to separate Azure Event Hubs for “events” and “samples” data records.
Before we begin the rest of the discussion, we would like to emphasize that the solution of an “analytics” problem is dependent on each plant, line, machine, and so on. The data must be available and be what the business needs. We will cover two different approaches for organizing the data, but they are not exhaustive, and are meant as examples only.
Storing the raw data
Our sample implementation has a basic set of Azure Stream Analytics queries that takes the incoming data stream from the Event Hubs that the raw data is posted to and copies it into Azure Storage blobs and tables. As an example, the queries look like the following:
SELECT
*
INTO
[samplesTable]
FROM
[EventHubIn]
One table is for samples and another is for events. As we were flattening the incoming data in the custom component, we added a property for the hour window the incoming data stream was in, using the following C# code snippet to help us more easily organize the data on the processing pipelines:
HourWindow =
new DateTime(
sample.timestamp.Year,
sample.timestamp.Month,
sample.timestamp.Day,
sample.timestamp.Hour,
0,
0),
This data record field is especially useful in organizing the records on the Azure Storage Table, simply by using it as the partition key. We are using the sequence number of the incoming record as the row key. The object model for the storage tables are covered in the documentation, “Understanding the Table Service Data Model.” Please also see the documentation, “Designing a Scalable Partitioning Strategy for Azure Table Storage,” for the recommendations on the storage table design.
The Azure Blob Storage blobs generated by the ASA job are organized in containers for each hour, as a single blob for the data for the hour, in the comma separated values (CSV) format. We will be using these in the future for artificial intelligence (AI) needs.
Loading data into Azure SQL Database
We will be covering a basic way to incrementally load the records to an Azure SQL Database and later discuss potential ways for further processing them to create new aggregations and summary data.

Our goal is to provide a barebones approach to show how data can flow into data stores and demonstrate the technologies useful for this. Any analytics solution depends heavily on the context and requirements, but we will attempt to provide basic mechanisms to demonstrate the related Azure services.
Azure Data Factory (ADF) is a cloud integration service to compose data storage, movement, and processing services in automated data pipelines. We have a simple ADF pipeline that demonstrates the incremental loading of a table using a storage table as the source.

The pipeline has a lookup activity that performs the following query on the SQL Database:
select
CONVERT(
char(30),
case when max(SampleTimestamp) is null then '1/1/2010 12:00:00 AM'
else max(SampleTimestamp) end, 126) as LastLoad
from [Samples]
The style used in the CONVERT function, 126, denotes the timestamp value to be formatted as “yyyy-mm-ddThh:mi:ss.mmm,” which matches the string representation of the partition key value on the storage table. The query returns the last record that was transferred to the SQL database. We can then pass that value to the next activity to query the table storage to retrieve the new records.
Next is a “Copy Data” activity, which simply uses the returned value from the lookup activity, which is the value of the “LastLoad,” and makes the following table query for the source. Please refer to Querying Tables and Entities for details on querying storage tables.
SampleTimestamp gt datetime'@{formatDateTime(activity('LookupSamples').output.FirstRow.LastLoad, 'yyyy-MM-ddThh:mm:ss.fffZ')}'
Later, this activity maps the storage table columns (properties) to SQL Database table columns. This pipeline is scheduled to run every 15 minutes, thus incrementally loading the destination SQL Database table.
Processing examples
Further processing the raw data depends on the actual requirements. This section covers two potential approaches for processing and organizing the data to demonstrate the capabilities.
Let’s first start looking at the data we collect to discover the details. Notice that the raw data on the samples table is in the form of name/value pairs. The first query will give us the different sample types recorded by each machine.
SELECT DeviceName, ComponentName, SampleName, COUNT(SampleSequence) AS SampleCount FROM Samples GROUP BY DeviceName, ComponentName, SampleName ORDER BY DeviceName ASC, ComponentName ASC, SampleName ASC, SampleCount DESC
We observe there are eight machines, and each one is sending different sets of sample types. Following is the partial result of the preceding query. We analyzed the result a bit further in Microsoft Excel to give an idea of the relative counts of the samples:

We may conclude that the best way to aggregate and summarize the results is first to organize the results by machine — for example, a raw data table per machine.
We will go step by step to demonstrate the concepts here. Some readers will surely find more optimized ways to implement some queries, but our goal here is to provide clear examples that demonstrate the concepts.
We may wish to process the data further by first transposing the raw data, which is in name/value pairs, as follows:

We can use the following query to create a new table and transpose whole rows. This query assumes that we do not differentiate any of the components and see the machine as a whole:
; WITH Machine08SamplesTransposed AS
(
SELECT * FROM
(
SELECT SampleTimestamp, sampleName, CAST(sampleValue AS NUMERIC(20,3)) AS sampleValueNumeric
FROM Samples
WHERE
DeviceName = 'Machine08' and ISNUMERIC(sampleValue) != 0
) AS S
PIVOT(
MAX(sampleValueNumeric)
FOR SampleName IN ([S2temp],
[Stemp],
[Zabs],
[Zfrt],
[S2load],
[Cfrt],
[total_time],
[Xabs],
[Xload],
[Fact],
[Cload],
[cut_time],
[Zload],
[S2rpm],
[Srpm],
[auto_time],
[Cdeg],
[Xfrt],
[S1load])
) AS PivotTable
)
SELECT * INTO Machine08Samples
FROM Machine08SamplesTransposed
We can bring this query into the ADF pipeline by moving it into a stored procedure with a parameter to query the raw table so that only the latest loaded rows are brought in, and modifying “SELECT * INTO …” to “INSERT * INTO …”. We recommend relying on stored procedures as much as possible to use SQL database resources efficiently.
The resulting table looks like the following (some columns removed for brevity).

One way to process this interim data set is to fill in the null values of samples from the last received value, as shown below.
We should emphasize that we are not recommending this solution for every business case and for every sample value. This approach makes sense for the values that are meaningful together. For example, in a certain case, grouping Fact (actual path feed-rate) and Zfrt (Z axis feed-rate) may make sense. However, for another case Xabs (absolute position on X axis) and Zfrt on one record, grouped this way, may not make sense. Grouping of the sample values must be done on a case-by-case basis, depending on the business need.

Or another way is to put the individual records into time buckets, and apply an aggregate function in that group:

Let’s give a small example for achieving the first option. In the preceding example, we received V1.1 at t1, and received V2.2 at t2. We want to fill in the Sample1 value for t2 with t1s, V1.1.
;WITH NonNullRank AS
(
SELECT SampleTimestamp, S2temp, cnt = COUNT(s2temp) OVER (ORDER BY SampleTimestamp)
FROM Machine08Samples
),
WindowsWithNoValues AS
(
SELECT SampleTimestamp, S2temp,
r = ROW_NUMBER() OVER (PARTITION BY cnt ORDER BY SampleTimestamp ASC) - 1
FROM NonNullRank
)
SELECT SampleTimestamp, S2temp,
S2tempWithValues= ISNULL(S2temp, LAG(S2temp, r) OVER (ORDER BY SampleTimestamp ASC))
FROM WindowsWithNoValues
When we dissect the preceding queries, the first common table expression (CTE), NonNullRank, gives us the rank of the non-null values of S2temp sample values among the received data records.
")
The second CTE, WindowsWithNoValues, gives us windows of samples with the received value at the top, and the order of null values within the windows (column r).

The concluding query fills in the null values using the LAG analytic function by bringing in the received value from the top of the window to the current row.

The second option we mentioned previously is to group the received values and apply an aggregate function within the group.
;WITH With30SecondBuckets AS
(
SELECT *,
(dateadd(second,(datediff
(second,'2010-1-1',[SampleTimestamp])/(30))*(30),'2010-1-1'))
AS [SampleTimestamp30Seconds]
FROM Machine08Samples
)
SELECT SampleTimestamp30Seconds, AVG(S2Temp)
FROM With30SecondBuckets GROUP BY SampleTimestamp30Seconds
ORDER BY SampleTimestamp30Seconds
We can put these queries in a stored procedure to generate new aggregate and summary tables as necessary to be used by the analytics solution.
We would like to repeat our opening argument here once more. The solution to an analytics problem depends on the available data, and what business needs. There may not be one single solution, but Azure provides many technology options for implementing a given solution.
Next steps
- Complete the ADF tutorial for transforming the data in the cloud by using a Spark activity and an on-demand Azure HDInsight linked service for a different example.
- Get the larger picture for extracting insights from IoT data from the solution guide.
Source: Azure Blog Feed