Read Replicas for Azure Database for PostgreSQL now in Preview
This blog is co-authored by Parikshit Savjani, Senior Program Manager and Rachel Agyemang, Program Manager, Microsoft Azure.
We are excited to announce Public Preview availability of Read Replicas for Azure Database for PostgreSQL.
Azure Database for PostgreSQL now supports continuous, asynchronous replication of data from one Azure Database for PostgreSQL server (the “master”) to up to five Azure Database for PostgreSQL servers (the “read replicas”) in the same region. This allows read-heavy workloads to scale out horizontally and be balanced across replica servers according to users' preferences. Replica servers are read-only except for writes replicated from data changes on the master. Stopping replication to a replica server causes it to become a standalone server that accepts reads and writes.
Key features associated with this functionality are:
- Turn-key addition and deletion of replicas.
- Support for up to five read replicas in the same region.
- The ability to stop replication to any replica to make it a stand-alone, read-write server.
- The ability to monitor replication performance using two metrics, Replica Lag and Max lag across Replicas.
For more information and instructions on how to create and manage read replicas, see the following articles:
- Read replicas in Azure Database for PostgreSQL
- How to create and manage read replicas in Azure Database for PostgreSQL using the Azure portal
We are sharing some of the application patterns and reference architectures which our customers and partners have implemented leveraging the read replicas for scaling out their workload.
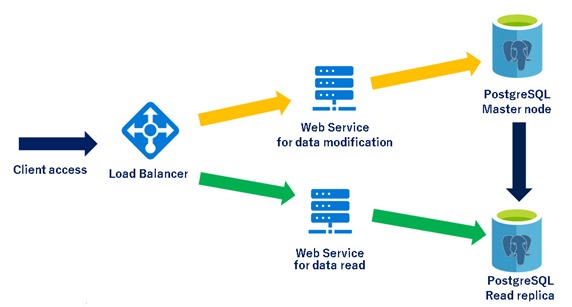
Microservices Pattern with Read scale Replicas
In this architecture pattern, the application is broken into multiple microservices with data modification APIs connecting to master server while reporting APIs connecting to read replicas. The data modification APIs are prefixed with “Set-” while reporting APIs are prefixed with “Get-“. The load balancer is used to route the traffic based on the API prefix.

BI Reporting
For BI Reporting workload, data from disparate data sources is processed every few mins and loaded in the master server. The master server is dedicated for loads and processing not directly exposing it to BI users for reporting or analytics to ensure predictable performance. The reporting workload is scaled out across multiple read replicas to manage high user concurrency with low latency.

IoT scenario
For IoT scenario, the high-speed streaming data is loaded first in master node as a persistent layer. The master server is used for high speed data ingestion. The read replicas are leveraged for reporting and downstream data processing to take data driven actions.

We hope that you enjoy working with the latest features and functionality available in our Azure database service for PostgreSQL. Be sure to share your impressions via User Voice for PostgreSQL.
Additional resources for Azure Database for PostgreSQL
Source: Azure Blog Feed