How Skype modernized its backend infrastructure using Azure Cosmos DB – Part 2
This is a three-part blog post series about how organizations are using Azure Cosmos DB to meet real world needs, and the difference it’s making to them. In part 1, we explored the challenges Skype faced that led them to take action. In this post (part 2 of 3), we examine how Skype implemented Azure Cosmos DB to modernize its backend infrastructure. In part 3, we’ll cover the outcomes resulting from those efforts.
Note: Comments in italics/parenthesis are the author's.
The solution
Putting data closer to users
Skype found the perfect fit in Azure Cosmos DB, the globally distributed NoSQL database service from Microsoft. It gave Skype everything needed for its new People Core Service (PCS), including turnkey global distribution and elastic scaling of throughput and storage, making it an ideal foundation for distributed apps like Skype that require extremely low latency at global scale.
Initial design decisions
Prototyping began in May 2017. Some early choices made by the team included the following:
- Geo-replication: The team started by deploying Azure Cosmos DB in one Azure region, then used its pushbutton geo-replication to replicate it to a total of seven Azure regions: three in North America, two in Europe, and two in the Asia Pacific (APAC) region. However, it later turned out that a single presence in each of those three geographies was enough to meet all SLAs.
- Consistency level: In setting up geo-replication, the team chose session consistency from among the five consistency levels supported by Azure Cosmos DB. (Session consistency is often ideal for scenarios where a device or user session is involved because it guarantees monotonic reads, monotonic writes, and read-your-own-writes.)
- Partitioning: Skype chose UserID as the partition key, thereby ensuring that all data for each user would reside on the same physical partition. A physical partition size of 20GB was used instead of the default 10GB size because the larger number enabled more efficient allocation and usage of request units per second (RU/s)—a measure of pre-allocated, guaranteed database throughput. (With Azure Cosmos DB, each collection must have a partition key, which acts as a logical partition for the data and provides Azure Cosmos DB with a natural boundary for transparently distributing it internally, across physical partitions.)
Event-driven architecture based on Azure Cosmos DB change feed
In building the new PCS service, Skype developers implemented a micro-services, event-driven architecture based on change feed support in Azure Cosmos DB. Change feed works by “listening” to an Azure Cosmos DB container for any changes and outputting a sorted list of documents that were changed, in the order in which they were modified. The changes are persisted, can be processed asynchronously and incrementally, and the output can be distributed across one or more consumers for parallel processing. (Change Feed in Azure Cosmos DB is enabled by default for all accounts, and it does not incur any additional costs. You can use provisioned RU/s to read from the feed, just like any other operation in Azure Cosmos DB.)
“Generally, an event-driven architecture uses Kafka, Event Hub, or some other event source,” explains Kaduk. “But with Azure Cosmos DB, change feed provided a built-in event source that simplified our overall architecture.”
To meet the solution’s audit history requirements, developers implemented an event sourcing with capture state pattern. Instead of storing just the current state of the data in a domain, this pattern uses an append-only store to record the full series of actions taken on the data (the “event sourcing” part of the pattern), along with the mutated state (i.e. the “capture state”). The append-only store acts as the system of record and can be used to materialize domain objects. It also provides consistency for transactional data, and maintains full audit trails and history that can enable compensating actions.
Separate read and write paths and data models for optimal performance
Developers used the Command and Query Responsibility Segregation (CQRS) pattern together with the event sourcing pattern to implement separate write and read paths, interfaces, and data models, each tailored to their relevant tasks. “When CQRS is used with the Event Sourcing pattern, the store of events is the write model, and is the official source of information capturing what has happened or changed, what was the intention, and who was the originator,” explains Kaduk. “All of this is stored on one JSON document for each changed domain aggregate—user, person, and group. The read model provides materialized views that are optimized for querying and are stored in a second, smaller JSON documents. This is all enabled by the Azure Cosmos DB document format and the ability to store different types of documents with different data structures within a single collection.” Find more information on using Event Sourcing together with CQRS.
Custom change feed processing
Instead of using Azure Functions to handle change feed processing, the development team chose to implement its own change feed processing using the Azure Cosmos DB change feed processor library—the same code used internally by Azure Functions. This gave developers more granular control over change feed processing, including the ability to implement retrying over queues, dead-letter event support, and deeper monitoring. The custom change feed processors run on Azure Virtual Machines (VMs) under the “PaaS v1” model.
“Using the change feed processor library gave us superior control in ensuring all SLAs were met,” explains Kaduk. “For example, with Azure Functions, a function can either fail or spin-and-wait while it retries. We can’t afford to spin-and-wait, so we used the change feed processor library to implement a queue that retries periodically and, if still unsuccessful after a day or two, sends the request to a ‘dead letter collection’ for review. We also implemented extensive monitoring—such as how fast requests are processed, which nodes are processing them, and estimated work remaining for each partition.” (See Frantisek’s blog article for a deeper dive into how all this works.)
Cross-partition transactions and integration with other services
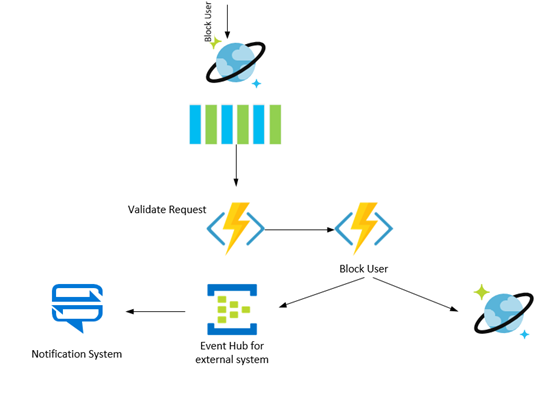
Change feed also provided a foundation for implementing background post-processing, such as cross-partition transactions that span the data of more than one user. The case of John blocking Sally from sending him messages is a good example. The system accepts the command from user John to block user Sally, upon which the request is validated and dispatched to the appropriate handler, which stores the event history and updates the query able data for user John. A postprocessor responsible for cross-partition transactions monitors the change feed, copying the information that John blocked Sally into the data for Sally (which likely resides in a different partition) as a reverse block. This information is used for determining the relationship between peers. (More information on this pattern can be found in the article, “Life beyond Distributed Transactions: an Apostate’s Opinion.”)
Similarly, developers used change feed to support integration with other services, such as notification, graph search, and chat. The event is received on background by all running change feed processors, one of which is responsible for publishing a notification to external event consumers, such as Azure Event Hub, using a public schema.

Migration of user data
To facilitate the migration of user data from SQL Server to Azure Cosmos DB, developers wrote a service that iterated over all the user data in the old PCS service to:
- Query the data in SQL Server and transform it into the new data models for Azure Cosmos DB.
- Insert the data into Azure Cosmos DB and mark the user’s address book as mastered in the new database.
- Update a lookup table for the migration status of each user.
To make the entire process seamless to users, developers also implemented a proxy service that checked the migration status in the lookup table for a user and routed requests to the appropriate data store, old or new. After all users were migrated, the old PCS service, the lookup table, and the temporary proxy service were removed from production.

Migration for production users began in October 2017 and took approximately two months. Today, all requests are processed by Azure Cosmos DB, which contains more than 140 terabytes of data in each of the replicated regions. The new PCS service processes up to 15,000 reads and 6,000 writes per second, consuming between 2.5 million and 3 million RUs per second across all replicas. A process monitors that RU usage automatically scaling allocated RUs up or down as needed.
Continue on to part 3, which covers the outcomes resulting from Skype’s implementation of Azure Cosmos DB.
Source: Azure Blog Feed