Multi-language identification and transcription in Video Indexer
Multi-language speech transcription was recently introduced into Microsoft Video Indexer at the International Broadcasters Conference (IBC). It is available as a preview capability and customers can already start experiencing it in our portal. More details on all our IBC2019 enhancements can be found here.
Multi-language videos are common media assets in the globalization context, global political summits, economic forums, and sport press conferences are examples of venues where speakers use their native language to convey their own statements. Those videos pose a unique challenge for companies that need to provide automatic transcription for video archives of large volumes. Automatic transcription technologies expect users to explicitly determine the video language in advance to convert speech to text. This manual step becomes a scalability obstacle when transcribing multi-language content as one would have to manually tag audio segments with the appropriate language.
Microsoft Video Indexer provides a unique capability of automatic spoken language identification for multi-language content. This solution allows users to easily transcribe multi-language content without going through tedious manual preparation steps before triggering it. By that, it can save anyone with large archive of videos both time and money, and enable discoverability and accessibility scenarios.
Multi-language audio transcription in Video Indexer
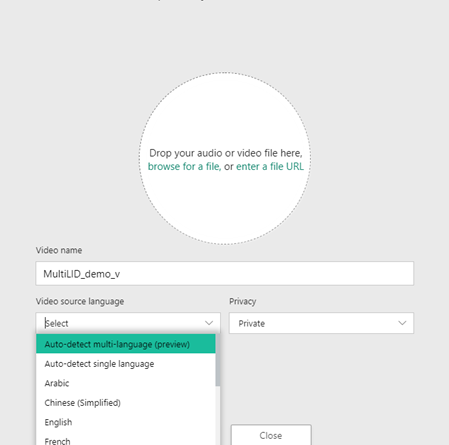
The multi-language transcription capability is available as part of the Video Indexer portal. Currently, it supports four languages including English, French, German and Spanish, while expecting up to three different languages in an input media asset. While uploading a new media asset you can select the “Auto-detect multi-language” option as shown below.

Our application programming interface (API) supports this capability as well by enabling users to specify 'multi' as the language in the upload API. Once the indexing process is completed, the index JavaScript object notation (JSON) will include the underlying languages. Refer to our documentation for more details.
Additionally, each instance in the transcription section will include the language in which it was transcribed.

Customers can view the transcript and identified languages by time, jump to the specific places in the video for each language, and even see the multi-language transcription as video captions. The result transcription is also available as closed caption files (VTT, TTML, SRT, TXT, and CSV).

Methodology
Language identification from an audio signal is a complex task. Acoustic environment, speaker gender, and speaker age are among a variety of factors that affect this process. We represent audio signal using a visual representation, such as spectrograms, assuming that, different languages induce unique visual patterns which can be learned using deep neural networks.
Our solution has two main stages to determine the languages used in multi-language media content. First, it employs a deep neural network to classify audio segments with very high granularity, in other words, very few seconds. While a good model will successfully identify the underlying language, it can still miss-identify some segments due to similarities between languages. Therefore, we apply a second stage for examining these misses and smooth the results accordingly.

Next steps
We introduced a differentiated capability for multi-language speech transcription. With this unique capability in Video Indexer, you can become more effective about the content of your videos as it allows you to immediately start searching across videos for different language segments. During the coming few months, we will be improving this capability by adding support for more languages and improving the model’s accuracy.
For more information, visit Video Indexer’s portal or the Video Indexer developer portal, and try this new capability. Read more about the new multi-language option and how to use it in our documentation.
Please use our UserVoice to share feedback and help us prioritize features or email visupport@microsoft.com with any questions.
Source: Azure Blog Feed