Advancing global network reliability through intelligent software—part 1 of 2
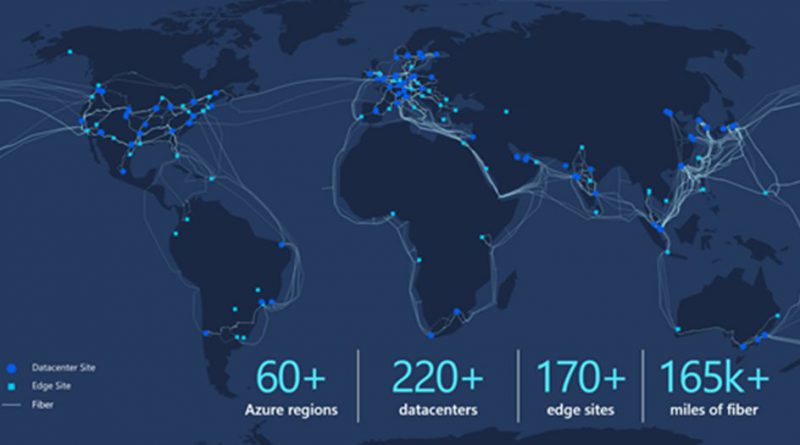
“Microsoft’s global network connects over 60 Azure regions, over 220 Azure data centers, over 170 edge sites, and spans the globe with more than 165,000 miles of terrestrial and subsea fiber. The global network connects to the rest of the internet via peering at our strategically placed edge points of presence (PoPs) around the world. Every day, millions of people around the globe access Microsoft Azure, Office 365, Dynamics 365, Xbox, Bing, and many other Microsoft cloud services. This translates to trillions of requests per day and terabytes of data transferred each second on our global network. It goes without saying that the reliability of this global network is critical, so I’ve asked Principal Program Manager Mahesh Nayak and Principal Software Engineer Umesh Krishnaswamy to write this two-part post in our Advancing Reliability series. They explain how we’ve approached our network design, and how we’re constantly working to improve both reliability and performance.”—Mark Russinovich, CTO, Azure
Microsoft’s global network is analogous to a highway system. Highways connect major cities and roadways connect small cities to major cities. In this analogy, data centers grouped into Azure regions are the major cities, and the edge PoPs are the small cities. Networking assets in data centers, at the edge, and across the global network are one pool shared by all. Think of them as a common highway with multiple lanes that all vehicles can use. This allows us to share resources, adapt to changes, and develop features that benefit all customers. Internet service providers, cloud providers, and content delivery networks have similar networks—some global and some local, so we link up with their networks at edge PoPs. Traffic moving between our data centers, and traffic between any one data center and the edge, all stays on Microsoft’s highway system.

Network system reliability is a top priority for us, and we are continuously making improvements to our systems. Although network incidents at our hyperscale are inevitable, we take these opportunities to learn from the various contributing factors and re-think our availability design principles to make our services even more reliable. In early October 2020, we experienced a rare service incident that caused network congestion on some routes for a short duration, which impacted other Microsoft cloud services. There are great learnings from this particular issue, and we have incorporated those learnings in our software and processes—and called them out below.
Key design principles
Like a highway system that offers fast and reliable transportation to passengers, we have designed our global network to provide maximum reliability and performance with the following guidelines.
- Well-provisioned network with redundant topology: Design hardware and software failure domains with redundancy, to handle multiple simultaneous failures and eliminate single points of failure. Design the network with enough capacity to meet service level objectives during times of high demand or crisis.
- De-risk changes: Change is constant in a large-scale network. However, small changes can lead to major, unforeseen repercussions. Follow safe deployment practices to reduce blast radii, have automatic rollbacks, allow sufficient bake time between deployment phases, and eliminate manual touches.
- Intelligent software systems to manage, monitor, and operate the network: The physical infrastructure is always prone to risks such as fiber cuts, hardware failure, demand surges, destructive weather events, and sabotage. Build software systems that maintain real-time views of topology, demands, traffic routing, failures, performance, and automatically recover from network events.
- Proximity: Customer traffic should flow on the global network for the bulk of its journey, so that we can control the network performance. All inter-regional traffic stays entirely within our network.
- Feedback loop and using AI to improve: Continuous learning is critical to our reliability mission. Every incident is thoroughly analyzed to determine root cause(s) and any contributing factors; understanding what went wrong is an important learning opportunity. Use self-learning with telemetry data to perform quicker triage, deeper analysis, and engage human operators.
De-risking changes
Change is both inevitable and beneficial given the need to deploy service updates and improvements, and to react quickly to vulnerabilities or incidents. Changes roll out gradually beginning with integration environments, canary regions, and building up to mass roll out. The change process is declarative through our Zero Touch Operations systems. The validation cycle uses Open Network Emulator for a complete emulation of the global network, and our Real time Operation Checker validates the risk of each change to the network.
Open Network Emulator (ONE)—software emulation of the network
When astronauts prepare for space missions, they practice each move and test every procedure on high-fidelity emulators. Similarly, when we make a change to our network, we validate it on high-fidelity network emulators. The entire global network can be instantiated in a software emulation environment called One Network Emulator (ONE). Network devices are emulated with images of their software running in containers and virtual machines in Azure. Multiple network devices are emulated on a single host, which enables us to instantiate the entire network for large scale testing. Network links are emulated with Virtual Extensible LAN (VXLAN) tunnels. Network topology and device configurations are downloaded from production configuration systems. Software controllers interact with ONE, oblivious that they are interacting with emulated devices. ONE allows us to do large scale tests before entering production. Every team has its independent ONE environment for continuous integration. ONE can also interoperate with real devices and be used to test the actual hardware.

Imagine that a team wants to upgrade network device software, deploy a patch, make a new configuration change, or deploy new controller software. The entire method of procedure to perform the change and roll back the change is tested in ONE. ONE has surfaced bugs in configuration, device software, inter-operability between devices, and scaling issues. Validation in ONE is integrated in our safe deployment framework.
In reference to the recent service incident (10/7 Issues accessing Microsoft and Azure services) mentioned in the introduction, the incident was caused by a code defect in a version update of a component that controls network traffic routing between Azure regions, but only at production scale and scope. To catch issues like this that happen rarely, we use a pre-production validation process to force similar issues to happen frequently in a virtualized environment by performing chaos testing. In chaos testing, bursts of random failures are introduced to see whether the network recovers back to a healthy state. Since this incident, we have increased test coverage and bake time in ONE to improve the resiliency of the traffic engineering controllers.
Real Time Operation Checker (ROC)—network simulator
Real Time Operation Checker (ROC) validates the impact of any planned change or unplanned downtime to the real-time network. For example, ROC answers the question “is it safe to offline a node or link for the next two hours?” The answer depends on the current condition of the network, other changes that have been allowed to proceed, network demands for the next two hours, and the risk of new failures causing isolation or congestion. While ONE emulates, ROC simulates.
ROC uses live topology and demand feeds and simulates device forwarding and queuing, and software controller behavior under failure and load scenarios. These simulations are parallelized using Azure Batch and results are available in minutes. ROC tokens are granted for human-initiated and service-initiated changes, and no network change can proceed without a ROC token. Maintenance by our fiber provider partners are also simulated in ROC to measure risk and take corrective actions in daily operations.
Zero Touch Operations
When operating a network of our size, manual configuration changes must be avoided. The network is too large for a human to watch and react to all health signals and determine if the configuration change had the intended outcome. Automated changes are delivered to the network by a software system, wrapped in pre and post checks to analyze safety and health before and after the change. Changes are rolled back immediately or blocked if health signals fail.
Automated changes are applied using three services—internally named Fuse, Clockwerk, and WARP. Fuse’s strength is performing repeatable tasks like upgrading network device software. In addition to being safer, Fuse is faster and frees up engineers. Clockwerk and WARP specialize in human-centered or ad-hoc changes. Engineers write stateful workflows to execute a sequence of changes wrapped in automatic checks and rollbacks. Users interact with the workflow over a modern web interface to provide human input within the workflow. An example of such a workflow is replacing hardware in a network device which requires traffic to be drained from the device before a technician replaces the hardware, then traffic restored back to the device in a safe manner. When changes are needed for an interactive repair operation, engineers enter their commands in a virtual console which are again peer reviewed and wrapped inside safety checks before sending to the devices. These systems all work together to eliminate the need to make a manual change.
All automated changes leverage the ROC framework as well as a myriad of canaries, monitors, and other health signals to analyze changes constantly to ensure the intent was delivered without adverse impact to customers—enabling a roll back at the slightest hint of impact.
Capacity planning
Capacity prediction and deployment velocity is vital to providing maximum reliability and performance. In our highway system analogy, capacity planning is about determining where to add lanes or new highways, how many to add, when they should be ready for traffic, and which ones to close.
Our capacity planning process begins by setting the topology of the network. The Topology Analysis system uses availability metrics from our network and external sources, new Azure region buildouts, and outside-in latency measurements, to generate future topologies. A demand prediction platform generates traffic matrices for multiple months using different algorithms, scores them against actuals, and creates a blended forecast. Optimized Repeatable Compiler for Augmentation Support (ORCAS) runs large-scale network simulations for future demands and topology. ORCAS programmatically assesses reliability, utilization, and efficiency and proposes how to evolve the network across more than 120,000 backbone routes and 6,000 shared risk link groups (SRLG).
Thousands of failure scenarios, involving multiple failing entities, are simulated along with the reaction of the traffic management controllers to determine the capacity needed for the worst-case failures. Historical performance data such as mean-time-between-failure (MTBF) and mean-time-to-repair (MTTR) are used to optimize the capacity requirement in both the short and long term. This signal is fed into our capacity workflow automation engine to complete the capacity delivery in a timely manner. This end-to-end system was used extensively to respond to the demand surge from COVID-19 and delivered 110 Tbps of additional backbone capacity in less than two months.
Optical fiber path diversity is extremely important to ensure reliable capacity. Fiber paths are like the pavement that supports the roads; flooded pavement affects all roads using it. Geo spatial information on fiber paths and other metadata on fiber cross points, power, and conduits is used to compute shared risks. We actively track the coverage of this data and maintain freshness in partnership with our fiber partners.
Conclusion
Reliable network connectivity is essential for a seamless, always-on cloud service experience. We have built a software driven cloud-scale network that gives us more flexibility and control to support the rapid growth and constantly evolving nature of cloud demands.
In part two, we’ll go deeper into software-managed traffic management, optimizing last mile resilience, detecting and remediating route anomaly detection, bandwidth broker Quality of Service (QoS), and continuous monitoring.
Source: Azure Blog Feed