Replicated Tables now generally available in Azure SQL Data Warehouse
We are excited to announce that Replicated Tables, a new type of table distribution, are now generally available in Azure SQL Data Warehouse (SQL DW). SQL DW is a fully managed, flexible, and secure cloud data warehouse tuned for running complex queries fast and across petabytes of data.
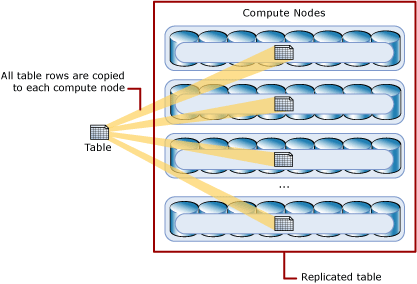
The key to performance for large-scale data warehouses is how data is distributed across the system. When queries join across tables and data is distributed differently, data movement is required to complete the query. The same can be said when transforming data to load, enrich, and apply business rules. With Replicated Tables, the data is available on all compute nodes, hence data movement is eliminated, and queries run faster. In some cases, such as small dimension tables, choosing a Replicated Table versus a Round Robin table, can increase performance because data movement is reduced. As with all optimization techniques, performance gains may vary and should be tested.

Reducing data movement to boost performance
During the public preview of Replicated Tables, SQL Data Warehouse customers are seeing up to 5x performance gains while transforming data with Replicated Tables when compared to using Round Robin distribution.
Taking a look at an example of increased query performance using the TPC-H schema and Q2 query showcases the query benefits of replicated tables. Q2 per the TPC-H spec answers the following business question:
The Minimum Cost Supplier Query finds, in a given region, for each part of a certain type and size, the supplier who can supply it at minimum cost. If several suppliers in that region offer the desired part type and size at the same (minimum) cost, the query lists the parts from suppliers with the 100 highest account balances. For each supplier, the query lists the supplier’s account balance (name and nation), the part’s number and manufacturer, as well as the supplier’s address, phone number, and comment information.
From a schema implementation perspective, the query leverages three smaller tables that align with the design guidance documentation and are prime candidates for replicated tables including supplier, nation, and region. From a query perspective, these tables are accessed a total of six times to complete this query. Below is a query execution graph comparing the run times with and without replicated tables while running on DW400 with 1 TB scale-factor. Different SQL DW scale settings, TPC-H queries, and scale factors can produce different results.

For this query with cold cache (SQL buffer cache), performance improvement from Round Robin table distribution to replicated table distribution is 13x. The warm cache is over 100x faster. Data movement needed in the Round Robin case is a fixed cost, which is the primary reason the warm cached run further boosts performance. It is recommended that you follow the design guidance to understand how Replicated Tables work and ensure they are leveraged in the right scenarios for your workload.
Recreate dimensions as replicated tables
Previously, SQL Data Warehouse instances containing a smaller domain, reference, or dimension tables used the default round robin distribution. During query execution, data was copied to each compute node forcing queries to execute longer. Furthermore, system resources are taken away from other queries on the system to move the data. A dimension table such as a date dimension could be recreated with the following code sample:

Next steps
Replicated Tables are available in all versions of Azure SQL Data Warehouse. To get started:
- Visit the design guidance to learn more about Replicated Tables.
- Create an Azure SQL Data Warehouse to get started today.
- If you need help for a POC, contact us directly.
- Stay up-to-date on the latest Azure SQL Data Warehouse news and features by following us on Twitter @AzureSQLDW.
Source: Azure Blog Feed