Azure #HDInsight Interactive Query: simplifying big data analytics architecture
Fast Interactive BI, data security and end user adoption are three critical challenges for successful big data analytics implementations. Without right architecture and tools, many big data and analytics projects fail to catch on with common BI users and enterprise security architects. In this blog we will discuss architectural approaches that will help you architect big data solution for fast interactive queries, simplified security model and improved user adoption with BI users.
Traditional approach to fast interactive BI
Deep analytical queries processed on Hadoop systems have traditionally been slow. MapReduce jobs or hive queries are used for heavy processing of large datasets, however, not suitable for the fast response time required by interactive BI usage.
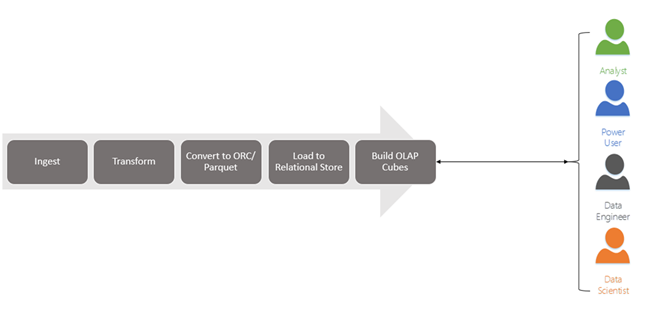
Faced with user dissatisfaction due to lack of query interactivity, data architects used techniques such as building OLAP cubes on top of Hadoop. An OLAP cube is a mechanism to store all the different dimensions, measures and hierarchies up front. Processing the cube usually takes place at the pre-specified interval. Post processing, results are available in advance, so once the BI tool queries the cube it just needs to locate the result, thereby limiting the query response time and making it a fast and interactive one. Since all measures get pre-aggregated by all levels and categories in the dimension, it is highly suitable for interactivity and fast response time. This approach is especially suitable if you need to light up summary views.

Above approach works for certain scenarios but not all. It tends to break down easily with large big data implementations, especially with use cases where many power users and data scientists are writing many ad-hoc queries.
Here are the key challenges:
-
OLAP cubes require precomputations for creating aggregates which introduces latency. Businesses across all industries are demanding more from their reporting and analytics infrastructure within shorter business timeframes. OLAP cubes can’t deliver real-time analysis.
-
In big data analytics, precomputation puts heavy burden on underlying Hadoop system creating unsustainable pressure on entire big data pipeline which severely hampers performance, reliability and stability of entire pipeline.
-
This type of architecture forces large dataset movement between different systems which works well at small scale. However, falls apart at large data scale. Keeping data hot and fresh across multiple tiers is challenging.
-
Power users and data scientists requires a lot more agility and freedom in terms of their ability to experiment using sophisticated ad-hoc queries that puts additional burden on overall system.
Azure HDInsight Interactive query overview
One of the most exciting new features of Hive 2 is Low Latency Analytics Processing (LLAP), which produces significantly faster queries on raw data stored in commodity storage systems such as Azure Blob store or Azure Data Lake Store.
This reduces the need to introduce additional layers to enable fast interactive queries.
Key benefits of introducing Interactive Query in your big data BI architecture:
Extremely fast Interactive Queries: Intelligent caching and optimizations in Interactive Query produces blazing-fast query results on remote cloud storage, such as Azure Blob and Azure Data Lake Store. Interactive Query enables data analysts to query data interactively in the same storage where data is prepared, eliminating the need for moving data from storage to another analytical engine for analytical needs. Refer to Azure HDInsight Performance Benchmarking: Interactive Query, Spark, and Presto to understand HDInsight Interactive Query performance expectations @ 100TB scale.
HDInsight Interactive Query (LLAP) leverages set of persistent daemons that execute fragments of Hive queries. Query execution on LLAP is very similar to Hive without LLAP, except that worker tasks run inside LLAP daemons, and not in containers.

Lifecycle of a query: After client submits the JDBC query, query arrives at Hive Server 2 Interactive which is responsible for query planning, optimization, as well as security trimming. Since each query is submitted via Hive Server 2, it becomes the single place to enforce security policies.

File format versatility and Intelligent caching: Fast analytics on Hadoop have always come with one big catch: they require up-front conversion to a columnar format like ORCFile, Parquet or Avro, which is time-consuming, complex and limits your agility.
With Interactive Query Dynamic Text Cache, which converts CSV or JSON data into optimized in-memory format on-the-fly, caching is dynamic, so the queries determine what data is cached. After text data is cached, analytics run just as fast as if you had converted it to specific file formats.
Interactive Query SSD cache combines RAM and SSD into a giant pool of memory with all the other benefits the LLAP cache brings. With the SSD Cache, a typical server profile can cache 4x more data, letting you process larger datasets or supporting more users. Interactive query cache is aware of the underlying data changes in remote store (Azure Storage). If underlying data changes and user issues a query, updated data will be loaded in the memory without requiring any additional user steps.

Concurrency: With the introduction of much improved fine-grain resource management, preemption and sharing cached data across queries and users, Interactive Query [Hive on LLAP] makes it better for concurrent users.
In addition, HDInsight supports creating multiple clusters on shared Azure storage and Hive metastore helps in achieving a high degree of concurrency, so you can scale the concurrency by simply adding more cluster nodes or adding more clusters pointing to same underlying data and metadata.
Please read Hive Metastore in HDInsight to learn more about sharing metastore across clusters and cluster types in Azure HDInsight.
Simplified and scalable architecture with HDInsight Interactive Query
By introducing Interactive Query to your architecture, you can now route power users, data scientists, and data engineers to hit Interactive Query directly. This architectural improvement will reduce the overall burden from the BI system as well as increases user satisfaction due to fast interactive query response as well as increases flexibility to run ad-hoc queries at will.

In above described architecture, users who wants to see the summary views can still be served with OLAP cubes. However, all other users leverage Interactive Query for submitting their queries.
For OLAP based applications on Azure HDInsight, please see solutions such as AtScale and Apache Kyligence.
Security model
Like Hadoop and Spark clusters, HDInsight Interactive Query leverages Azure Active Directory and Apache Ranger to provide fine-grain access control and auditing. Please read An introduction to Hadoop security article to understand security model for HDInsight clusters.
In HDInsight Interactive Query, access restriction logic is pushed down into the Hive layer and Hive applies the access restrictions every time data access is attempted. This helps simplify authoring of the Hive queries and provides seamless behind-the-scenes enforcement without having to add this logic to the predicate of the query. Please read Using Ranger to Provide Authorization in Hadoop to understand different type of security policies that can be created in Apache Ranger.
User adoption with familiar tools
In big data analytics, organizations are increasingly concerned that their end users aren’t getting enough value out of the analytics systems because it is often too challenging and requires using unfamiliar and difficult-to-learn tools to run the analytics. HDInsight Interactive Query addresses this issue by requiring minimal to no new user training to get insight from the data. Users can write SQL queries (hql) in the tools they already use and love the most. HDInsight Interactive query out of the box supports BI tools such as Visual Studio Code, Power BI, Apache Zeppelin, Visual Studio, Ambari Hive View, Beeline, and Hive ODBC.

To learn more about these tools, please read Azure HdInsight Interactive Query: Ten tools to analyze big data faster.
Built to complement Spark, Hive, Presto, and other big data engines
HDInsight Interactive query is designed to work well with popular big data engines such as Apache Spark, Hive, Presto, and more. This is especially useful because your users may choose any one of these tools to run their analytics. With HDInsight’s shared data and metadata architecture, users can create multiple clusters with the same or different engine pointing to same underlying data and metadata. This is very powerful concept as you are no longer bounded by one technology for analytics.

Try HDInsight now
We hope you will take full advantage fast query capabilities of HDInsight Interactive Query. We are excited to see what you will build with Azure HDInsight. Read this developer guide and follow the quick start guide to learn more about implementing these pipelines and architectures on Azure HDInsight. Stay up-to-date on the latest Azure HDInsight news and features by following us on Twitter #HDInsight and @AzureHDInsight. For questions and feedback, please reach out to AskHDInsight@microsoft.com.
About HDInsight
Azure HDInsight is Microsoft’s premium managed offering for running open source workloads on Azure. Azure HDInsight powers mission critical applications ranging in a wide variety of sectors including, manufacturing, retail education, nonprofit, government, healthcare, media, banking, telecommunication, insurance, and many more industries ranging in use cases from ETL to Data Warehousing, from Machine Learning to IoT, and more.
Additional resources
- Get started with HDInsight Interactive Query Cluster in Azure
- Azure HDInsight Performance Benchmarking: Interactive Query, Spark and Presto
- Learn more about Azure HDInsight
- Use Hive on HDInsight
- Open Source component guide on HDInsight
- HDInsight release notes
- Ask HDInsight questions on Msdn forums
- Ask HDInsight questions on stackoverflow
Source: Azure Blog Feed