Video Indexer – General availability and beyond
Earlier today, we announced the general availability (GA) of Video Indexer. This means that our customers can count on all the metadata goodness of Video Indexer to always be available for them to use when running their business. However, this GA is not the only Video Indexer announcement we have for you. In the time since we released Video Indexer to public preview in May 2018, we never stopped innovating and added a wealth of new capabilities to make Video Indexer more insightful and effective for your video and audio needs.
Delightful experience and enhanced widgets
The Video Indexer portal already includes insights and timeline panes that enables our customers to easily review and evaluate media insights. The same experience is also available in embeddable widgets, which are a great way to integrate Video Indexer into any application.
We are now proud to release revamped insight and timeline panes. The new insight and timeline panes are built to accommodate the growing number of insights in Video Indexer and are automatically responsive to different form factors.

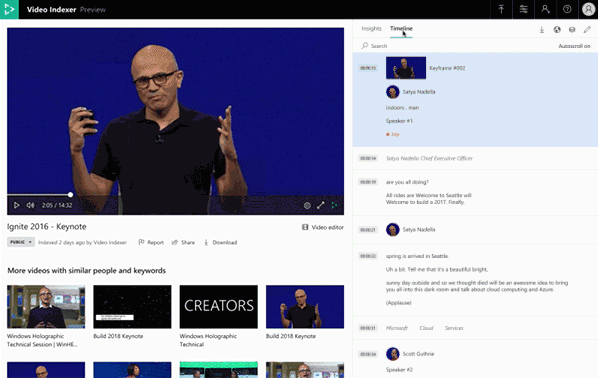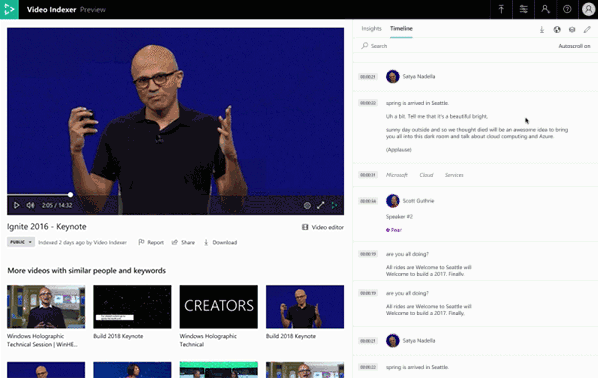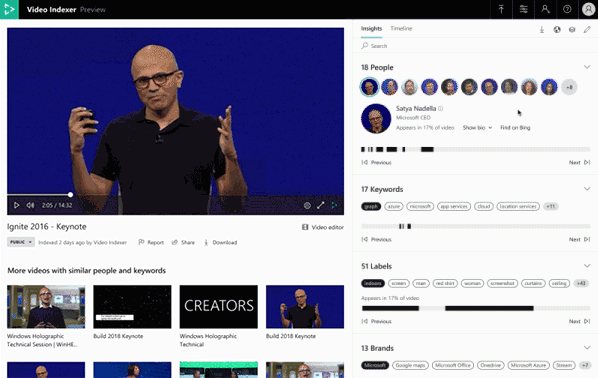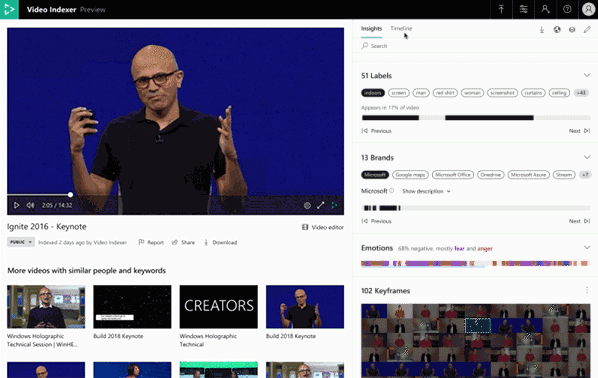
By the way, with the new insight pane we have also added visualizations for the already existing keyframes extraction capability, as well as new emotion detection insights. Which brings us to the next set of announcements.
Richer insights unlocked by new models
The core of Video Indexer is of course the rich set of cross-channel (audio, speech, and visual) machine learning models it provides. We are working hard to continue adding more models, and make improvements to our existing models, in order to provide our customers with more insightful metadata on their videos!
Our most recent additions to Video Indexer’s models are the new emotion detection and topic inferencing models. The new emotion detection model detects emotional moments in video and audio assets based on two channels, speech content and voice tonality. It divides them into four emotional states – anger, fear, joy, and sadness. As with other insights detected by Video Indexer, we provide the exact timeframe for each emotion detected in the video and the results are available both in the JSON file we provide for easy integration and in the insight and timeline experiences to be reviewed in the portal, or as embeddable widgets.

Another important addition to Video Indexer is the ability to do topic inferencing. That is, understand the high-level topics of the video or audio files based on the spoken words and visual cues. This model is different than the keywords extraction model that already exists in Video Indexer. It detects topics in various granularities (e.g. Science, Astronomy, or Missions to Mars) that are inferred from the assets, but not necessarily appear in it, while the keywords extracted will be specific terms that actually appeared in the content. Our topics catalog for this model is sourced from multiple resources, including the IPTC media topics taxonomy, in order to provide the media standard topics.
Note that today’s topics exist in the JSON file. To try them out, simply download the file using the curly braces button below the player or from the API, and search for the topics hammock. Stay tuned for updates on the new user portal experience we are working on!
In addition to the newly released models, we are investing in the improvement of existing models. One of those models is the well-loved celebrity recognition model, which we recently enhanced to cover approximately one million faces based on commonly requested data sources such as IMDB, Wikipedia, and top LinkedIn influencers. Try it out, and who knows maybe you are one of them!

Another model that was recently enhanced is the custom language model that allows each of our customers to extend the speech-to-text performance of Video Indexer to its own specific content and industry terms. Starting last month, we extended this custom language support to 10 different languages including English, Spanish, Italian, Arabic, Hindi, Chinese, Japanese, Portuguese, and French.
Another important model we recently released is the automatic identification of the spoken language in video. With that new capability customers can easily index batches of videos, without manually providing their language. The model automatically identifies the main language used and invokes the appropriate speech-to-text model.

Easily manage your account
Video Indexer accounts relay on Azure Media Services accounts and use their different components as infrastructure to perform encoding, computation, and streaming of the content as needed.
For easier management of the Azure Media Services resources used by Video Indexer, we recently added visibility into the relevant configuration and states from within the Video Indexer portal. From here you can see at any given time what media resource is used for your indexing jobs, how many reserved units are allocated for indexing and of what type, how many indexing jobs are currently running, and how many are queued.
Additionally, if we identify any configuration that might interfere with your indexing business needs, we will surface those as warnings and errors with a link to the location within your Azure portal to tend to the identified issue. This may include cases such as Event Grid notification registration missing in your subscription, Streaming Endpoints disabled, Reserved Units quantity, and more.
To try it out, simply go to your account settings in the Video Indexer portal and choose the account tab.
 1.7")
In that same section, we also added the ability to auto-scale the computation units used for indexing. That means that you can allocate the maximum amount of computation reserved units in your Media Services account, and Video Indexer will stop and start them automatically as needed. As a result, you won’t pay extra money for idle time and you will not have to wait for indexing jobs to complete when the indexing load is high.
Another addition that can help customers who wish to only extract insights, without the need to view the content, is the no streaming option. If this is the case for you, you can now use this newly added parameter while indexing to avoid the encoding costs, as well as get faster indexing. Please note that selecting this option will prevent your video from playing in the portal player. So if the portal or widgets are leveraged in your solution, you would probably want to keep streaming enabled.
Minimal integration effort
With the public preview a few months back, we also released a new and improved Video Indexer v2 RESTful API. This API enables quick and easy integration of Video Indexer to your application, on either client-to-server or server-to-server architecture.
Following that API, we recently released a new Video Indexer v2 connector for Logic Apps and Flow. You can set up your own custom Video Indexer workflows to further automate the process of extracting deep insights from your videos quickly and easily without writing a single line of code!
Learn more about the new connector and try out example templates.

To make the integration with Video Indexer fit your current workflow and existing infrastructure, we also expanded our closed caption and subtitle file format support with the addition of Sub Rip Text (SRT) and W3C Timed Text (TTML) file formats. Get more information on how to extract the different caption and subtitle formats.
What’s next?
The GA launch is just the beginning. As you can see from this blog there is a lot that we have already done, yet there is a whole lot more that we are actively working on! We are excited to continue this journey together with our partners and customers to enhance Video Indexer and make your video and audio content more discoverable, insightful, and valuable to you.
Have questions or feedback? We would love to hear from you! Use our UserVoice to help us prioritize features, or email VISupport@Microsoft.com for any questions.
Source: Azure Updates