Deep dive into Azure HDInsight 4.0
We are thrilled to announce that HDInsight 4.0 is now available in public preview. HDInsight 4.0 brings latest Apache Hadoop 3.0 innovations representing over 5 years of work from the open source community and our partner Hortonworks across key apache frameworks to solve ever-growing big data and advanced analytics challenges. With this release, we are bringing new enhancements to all big data open source frameworks on HDInsight.
This blog highlights new capabilities we are enabling for Apache Hive 3.0, Hive Spark Integration, Apache HBase and Apache Phoenix.
Apache Hive 3.0 improvements for fast queries and transactions
To date, driving comprehensive BI on historic and real-time data at scale remains a complex and challenging task. Many organizations have stitched together multiple open source and proprietary tools in order to build a workable BI solution. These solutions often require tedious data movement, complex pipeline management, or continuous manual data tearing to keep data hot. They are often complex to build, difficult to operate, and hard to scale.
Our customers are increasingly looking for simpler yet powerful, enterprise-grade solutions. We at Microsoft are obsessed with the idea of enabling real-time analytics directly on top of data lakes, reducing the need for data movement for analytics, BI dashboards or complex ad-hoc SQL queries.
Hive LLAP (Low Latency Analytical Processing known as Interactive Query in HDInsight) delivers ultra-fast SQL queries on data stored in a variety of data sources without sacrificing the scalability Hive and Hadoop are known for. With Hive LLAP, customers can drive analytics involving complex joins, subqueries, windowing functions transformations, sorting, UDFs, and complex aggregations. Hive LLAP enables data analysts to query data interactively in the same storage where data is prepared, eliminating the need for moving data from storage to another engine for analytics.
The performance and scalability of Hive LLAP is well established. BI users and data scientists can use the tools they love the most to work with Hive on LLAP.
Hive 3.0 brings additional performance improvements, allowing BI users to easily drive deeper analytics on data lakes.
Result caching
Caching query results allow a previously computed query result to be re-used in the event that the same query is processed by Hive. This feature dramatically speeds up frequently used queries. When result caching is enabled, your cluster is saving compute resources and returning the previously cached results much more quickly, improving the performance of common queries submitted by users.
Dynamic materialized views
Hive now supports dynamic materialized views. Pre-computation of summaries (materialized views) is a query speed-up technique in traditional data warehousing systems. Once created, materialized views can be stored natively in Hive or in an Apache Druid layer, and they can seamlessly use LLAP acceleration. Then the optimizer relies on Apache Calcite to automatically produce full and partial rewritings for a large set of query expressions comprising projections, filters, joins, and aggregation operations.
Better data quality and GDPR compliance enabled by Apache Hive transactions
While the previous version of ACID (Atomicity, Consistency, Isolation, and Durability) in Hive needed specialized configurations such as enabling transactions and implementing bucketing, ACID v2 in Hive 3.0 brings performance improvements in both the storage format and execution engine with either equal or better performance when compared to non-ACID tables. ACID on is enabled by default to allow full support for data updates.
With improved ACID capabilities, our customers can better handle data quality (update/delete) issues at row level as well as meet compliance requirements such as GDPR with the ability to erase the data at row level.
- ACID (is default in Hive 3.0)
- No performance overhead
- No bucketing required
- Spark can read and write to Hive ACID tables via Hive Warehouse Connector
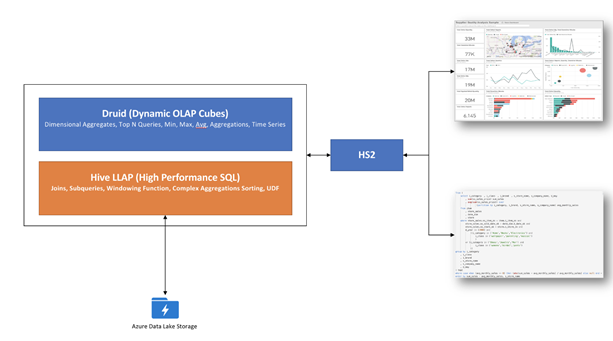
Apache Hive LLAP + Druid = single tool for multiple SQL use cases
Druid is a high-performance, column-oriented, distributed data store, which is well suited for user-facing analytic applications and real-time architectures. Druid is optimized for sub-second queries to slice-and-dice, drill down, search, filter, and aggregate event streams. Druid is commonly used to power interactive applications where sub-second performance with thousands of concurrent users are expected.
While Hive LLAP is great for providing an interactive experience on complex queries, it is not built to be an OLAP system. To provide a singular solution for both complex SQL and OLAP type queries, we are bringing Apache Druid Integration with Hive LLAP to HDInsight.
By combining Druid with LLAP in a single stack, we are enabling a powerful BI solution for our customers. Users and applications can use a JDBC endpoint to submit a query and depending upon the nature of query, the query can be answered by the Druid layer or LLAP layer.

Simple queries can be answered directly from Druid and benefit from Druid’s extensive OLAP optimizations. More complex operations will push work down into Druid when it can, then run the remaining bits of the query in Hive LLAP.
*Druid LLAP integration is not enabled in HDInsight 4.0 preview. Coming soon!
Apache Spark gets updatable tables and ACID transactions with Hive Warehouse Connector
The new integration between Apache Spark and Hive LLAP in HDInsight 4.0 delivers new capabilities for business analysts, data scientists, and data engineers. Business analysts get a performant SQL engine in the form of Hive LLAP (Interactive Query) while data scientists and data engineers get a great platform for ML experimentation and ETL with Apache Spark over transactional data in Hive tables. This integration closes one of the longstanding gaps in Apache Spark—the inability to perform table updates in a controlled transactional manner. While previously, the only functionality that was available was limited to table partition manipulation, now with Hive Warehouse Connector, users can register Hive transactional tables as external tables in Spark and get full transactional functionality on Spark.
Scenarios that can be enabled include:
- Want to run ML model training over the same transactional tables that business analysts use for reporting? You can do that now in Apache Spark on HDInsight 4.0.
- Want to add prediction scores or classification results from Spark ML as a column to the Hive table for business analysts to use? You can do that easily and with full guarantees of read consistency across concurrent users by initiating ACID transaction from Spark.
- Need to manage user data in accordance with GDPR in Apache Spark? Spark to Hive Warehouse Connector lets you do that as well.
- Want to run Spark Streaming jobs on the change feed from Hive Streaming tables? Even that is possible. Hive Warehouse Connector supports Streaming DataFrames for streaming reads and writes into transactional and streaming Hive tables from Spark.
- Need to create ORC files directly from Spark Structured Streaming job? This path is also possible thanks to the Hive compatible ORC writer available now in Apache Spark.
Under the covers, Hive Warehouse Connector is implemented as modern Apache Spark Data Source v2. It allows Spark executors to connect directly to Hive LLAP daemons to retrieve and update data in a transactional manner. This architecture is what allows the complete spectrum of Hive transactional features to be fully supported on the Spark side as it’s Hive that gets to keep control over the data in the end. The architecture prevents the typical issue of users accidentally trying to access Hive transactional tables directly from Spark, resulting in inconsistent results, duplicate data, or data corruption.
In the new world of HDInsight 4.0, Spark tables and Hive tables are kept in separate meta stores to avoid confusion of table types. The new architecture instead requires explicit registration of Hive transactional tables as Spark external tables through Hive Warehouse Connector. While it adds one extra step during configuration, this approach greatly increases the reliability of data access. Hive Warehouse Connector supports efficient predicate pushdown and Apache Arrow-based communication between Spark executors and Hive LLAP daemons. This results in overall small overhead of communication between two systems. With Hive Warehouse Connector, Apache Spark on HDInsight 4.0 gets mature transactional capabilities.

Apache HBase 2.0 and Apache Phoenix 5.0 gets new performance and stability features
We are introducing HBase 2.0 and Phoenix 5.0 in HDInsight 4.0 with several performance, stability, and integration improvements.
In-memory compactions improve performance. HBase 2.0 introduces in-memory compactions. In HBase, performance increases when data is kept in memory for a longer period of time and not flushed or read too often from remote cloud storage. Periodic reorganization of the data in the Memstore with in-memory compactions can result in a reduction of overall I/O as data is read and written less frequently from Azure Storage.
Faster performance with read/write path improvement. HBase 2.0 now implements fully off-heap read/write path. When data is written into HBase throughput operations, the cell objects do not enter JVM heap until the data is flushed to storage in an HFile. This helps to reduce total heap usage of a RegionServer and it copies less data, making it more efficient. Bucket cache can be configured as L1 or L2 cache.
Procedure V2. Procedure V2 is an updated framework for executing multi-step HBase administrative operations when there is a failure. You can use this framework to implement all the master operations using procedure v2 to remove the need for tools like hbck in the future.
Asynchronous Java client API. There is a new Java client API in HBase 2.0. This replaces the old Java NIO RPC server with a Netty RPC server. Netty RPC server provides you the ability to easily use an Asynchronous Java client API.
Apache Phoenix improvements. Phoenix 5.0 brings more visibility into queries with query log by introducing a new system table "SYSTEM.LOG" that captures information about queries that are being run against the cluster. Hive 3.0 is supported with Phoenix via updated phoenix-hive Storage Handler as well as Spark 2.3 is supported via the updated phoenix-spark driver.
Summary
HDInsight 4.0 is a significant release with many key enhancements. This blog post reviews just a subset of the capabilities we are enabling that will help our customers realize their big data visions. Please stay tuned for additional announcements about new capabilities we are bringing to HDInsight.
Try Azure HDInsight now
We are excited to see what you will build with Azure HDInsight. Read this developer guide and follow the quick start guide to learn more about implementing these pipelines and architectures on Azure HDInsight. Stay up-to-date on the latest Azure HDInsight news and features by following us on Twitter #HDInsight and @AzureHDInsight. For questions and feedback, please reach out to AskHDInsight@microsoft.com.
About Azure HDInsight
Azure HDInsight is an easy, cost-effective, enterprise-grade service for open source analytics that enables customers to easily run popular open source frameworks including Apache Hadoop, Spark, Kafka, and others. The service is available in 27 public regions and Azure Government Clouds in the US and Germany. Azure HDInsight powers mission-critical applications in a wide variety of sectors and enables a wide range of use cases including ETL, streaming, and interactive querying.
This blog post was co-authored by Maxim Lukiyanov (Principal Program Manager, Azure HDInsight)
Additional resources
- Ask HDInsight questions on MSDN forums
- Ask HDInsight questions on StackOverflow
- Open Source component guide on HDInsight
- Get started with HDInsight Interactive Query Cluster in Azure
- Azure HDInsight Performance Benchmarking: Interactive Query, Spark, and Presto
- Learn more about Azure HDInsight
- Use Hive on HDInsight
- HDInsight release notes
Source: Big Data