Two considerations for a serverless data streaming scenario
We recently published a blog on a fraud detection solution delivered to banking customers. At the core of the solution is the requirement to completely process a streaming pipeline of telemetry data in real time using a serverless architecture. Two technologies were evaluated for this requirement, Azure Stream Analytics and Azure Functions. This blog describes the evaluation process and the decision to use Azure Functions.
Scenario
A large bank wanted to build a solution to detect fraudulent transactions, submitted through their mobile phone banking channel. The solution is built on a common big data pipeline pattern. High volumes of real-time data are ingested into a cloud service, where a series of data transformations and extraction activities occur. This results in the creation of a feature, and the use of advanced analytics. For the bank, the pipeline had to be very fast and scalable where end-to-end evaluation of each transaction had to complete in less than two seconds.
Pipeline requirements include:
- Scalable and responsive to extreme bursts of ingested event activity. Up to 4 million events and 8 million or more transactions daily.
- Events were ingested as complex JSON files, each containing from two to five individual bank transactions. Each JSON file had to be parsed, and individual transactions extracted, processed, and evaluated for fraud.
- Events and transactions had to be processed in order, with guarantees that duplicates would not be processed. The reason for this requirement is that behavioral data was extracted from each transaction to create customer and account profiles. If events were not processed sequentially, the calculations and aggregations used to create the profiles and feature set for fraud prediction would be invalid and impact the accuracy of the machine learning model.
- Reference data and the ability to do dynamic look-ups was a critical component in the pipeline processing. For this scenario, reference data could be updated at any point during the day.
- An architecture that could be deployed with ARM templates, making integration with CI/CD and DevOps processes easier. A template architecture meant the entire fraud detection pipeline architecture could be easily redeployed to facilitate testing or to quickly extend the bank’s fraud detection capabilities to additional banking channels such as internet banking.
To meet these requirements, we evaluated Azure Stream Analytics and Azure Functions. Both technologies are managed services with similar capabilities:
- Easy configuration and setup.
- Designed to handle real-time, large-scale event processing.
- Out-of-the-box integration with Event Hubs, Azure SQL, Azure ML, and other managed services
Both technologies are well suited for a real-time streaming, big data scenario.
How did we do it?
It was important to explore both technologies to determine which one was a better fit for the specific situation. Two aspects to the solution required deep validation. How long does it take to process a single message end-to-end? And how many concurrent messages can be processed end-to-end?
We considered two initial architectural patterns:
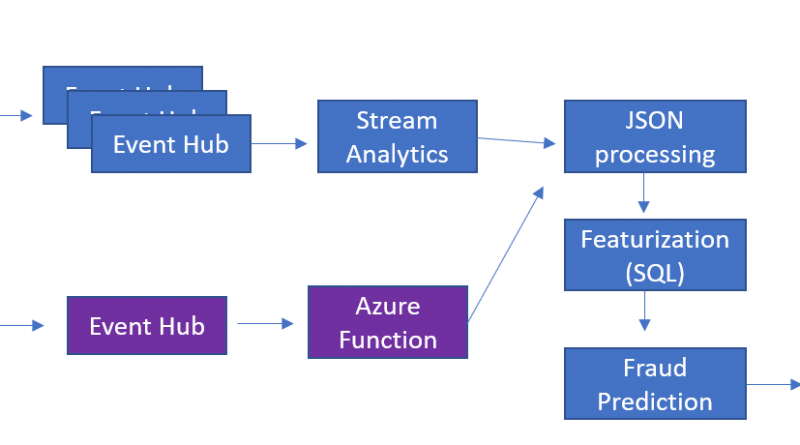
- Option #1 – Data streams into three instances of Event Hubs and is consumed by Azure Stream Analytics.
- Option #2 – Data streams into a single instance of Event Hubs and is consumed by a single Azure function.

In addition to the Azure services referenced previously, we drove the test harness using a message replayer to send events to Event Hub. With modifications to use data specifics for this scenario, we used TelcoGenerator, which is a call-event generation app downloadable from Microsoft. The source code is available on GitHub.
What did we learn?
Both Azure Stream Analytics and Azure Functions are easy to configure and within minutes can be set up to consume massive volumes of telemetry data from Azure Event Hub. Load testing was performed and results were captured using telemetry, was captured through Azure Application Insights. Key metrics clearly showed that Azure Functions delivered better performance and throughput for this particular workflow:
|
Architecture |
3 Event Hubs + Stream Analytics |
1 Event Hub + 1 Azure Function |
|
Minimum time to process a single message end to end (lower is better) |
8,000 millisecond |
69 millisecond |
|
Average number of events processed per minute (higher is better) |
300 |
8,300 |
Table: Load testing results
While some functionality overlaps occur between the two approaches, key differentiators that drove the selection of Azure Functions included the following:
- Both technologies provide the capability to process the pipeline in batches, but Azure Functions provides the ability to evaluate and execute one event at a time with millisecond latency. In addition, with Azure Functions, events were guaranteed to process in order.
- The coding paradigms are different. Azure Stream Analytics has a SQL-like query processing language and Azure Functions supports C#, JavaScript, Python, and other languages. For this solution, the Azure Function was written in C#, which enabled more sophisticated business logic beyond the query capabilities of windowing.
- An Azure Function integrated with Azure SQL provides multiple benefits:
- Transactional control over event and transaction processing. If processing errors were found with a transaction in an event, all the transactions contained in the event could be rolled back.
- Doing the bulk of data preparation using Azure SQL in-memory processing and native stored procedures was very fast.
- Dynamic changes to reference data or business logic are more easily accommodated with Azure Functions. Reference tables and the stored process could easily and quickly be updated in Azure SQL and used immediately in subsequent executions. With Azure Stream Analytics (ASA), these types of changes require modification of the ASA query and redeployment of the pipeline.
- JSON file processing was very intensive and complex, with up to five individual bank transactions extracted from each JSON file. JSON parsing tended to be much faster with Azure Function because it leverages native JSON capabilities in .NET Framework. Azure Stream Analytics also works with complex data types but processing with functions such as “GetArrayElement” are not as fast as native .NET functions.
- Both services had an initial issue with locking on the Event Hubs consumer groups when scaling. After experimenting with configuration parameters described in “A fast, serverless, big data pipeline powered by a single Azure Function”, a single function was all that was needed to meet the big data volume requirements for this solution.
- With an Azure Function, state can be more easily saved between processing activities.
- It is easier to incorporate an Azure Functions pipeline into a DevOps release process, and easier to develop unit tests for Azure Functions methods. For this scenario, it was helpful to develop unit tests for data values and data type checks for the Azure Function.
Recommended next steps
As solution requirements are refined, it can become important for technology decision makers to know how a data pipeline will perform with sudden fluctuations in an event and data volumes. As you consider technologies for your data pipeline solution, consider load testing the pipeline. To get you started, visit the following links:
- Alerting on fraudulent transactions is a common use case for Azure Stream Analytics. Get started using Azure Stream Analytics: Real-time fraud detection.
- An Event Hub/Azure Functions solution, but not the mobile bank solution.
- Read more on configuration parameters in A fast, serverless, big data pipeline powered by a single Azure Function.
- The full architecture for the bank fraud solution referenced in this blog can be found in the Mobile bank fraud solution guide.
Special thank you to Cedric Labuschagne, Chris Cook, and Eujon Sellers for their collaboration on this blog.
Source: Azure Blog Feed